Agentic AI 驅動新一波算力需求,AI 產業的算力競爭重心,正在從訓練移向推理(Inference)。推理效率也成為 Computex 2026 展會最核心的議題。
2025 年 12 月 24 日,Nvidia 以 200 億美元取得 Groq 的 Inference 技術授權與核心團隊。兩個月後,2026 年 2 月 20 日,加拿大 AI 晶片新創 Taalas 發表推理晶片 HC1,在 Llama 3.1 8B 模型實現 16,960 tokens/s/user 的極高速率,每百萬 tokens 推理成本約為 Nvidia B200 throughput optimized 模式的五分之一。2026 年 5 月 14 日,Cerebras 正式掛牌上市,市場再度將目光看向 AI Inference 晶片這個賽道。
從 Nvidia 的百億押注、新創的密集出場,到資本市場開始替這類公司定價,反映著在 AI 推理時代,產業競爭已從「更大」轉向「更有效率」的模型。本文將探討:
- AI 產業從訓練逐步邁向推理的發展趨勢
- 通用 GPU 的架構瓶頸
- 硬式編碼推理晶片優勢與挑戰
- 高效率 Inference 晶片新創公司比較
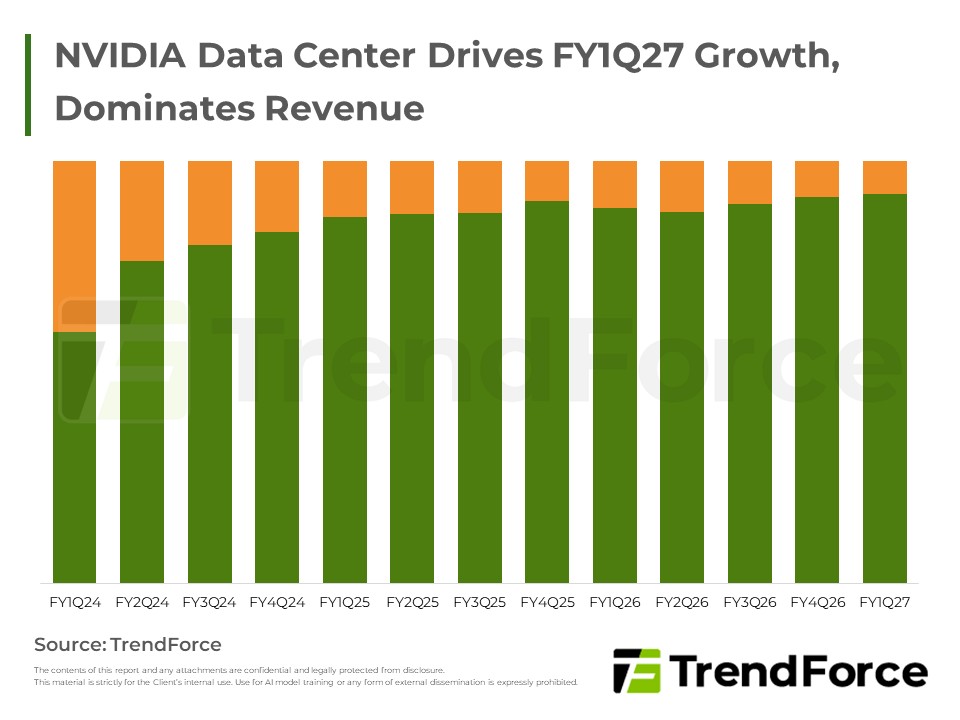
FY1Q27 NVIDIA AI 伺服器盤點:GB/VR Rack領軍
NVIDIA FY1Q27 營收創高,資料中心占比首度突破九成二;今年將主推 GB/VR Rack 整櫃方案,挹注液冷與 HBM供 應鏈進入長期結構性成長循環。
獲取最新動態產業重心位移:訓練導向轉為推理導向
2022 年生成式 AI 崛起初期,產業競爭聚焦於模型訓練,誰能訓練出更強模型,誰就握有話語權,於是廠商以巨額支出堆疊參數與晶片資源,換取模型規模與能力的躍升。
然而,隨著 AI 服務進入常態化部署,成本壓力的結構已改變。推理是高頻、長期與營收直接連動的成本中心,單位推理成本與能效表現將直接影響毛利率與規模擴張能力。 每一次 API 呼叫、每一個生成 token,都代表算力消耗與毛利壓力。若 token 生成成本無法隨規模下降,商業模式的存續將受到挑戰。
在此背景下,軟硬體發展焦點遂轉向吞吐量、能效比與記憶體架構優化,強調資料搬移效率與低延遲設計,而非單純追求峰值算力。
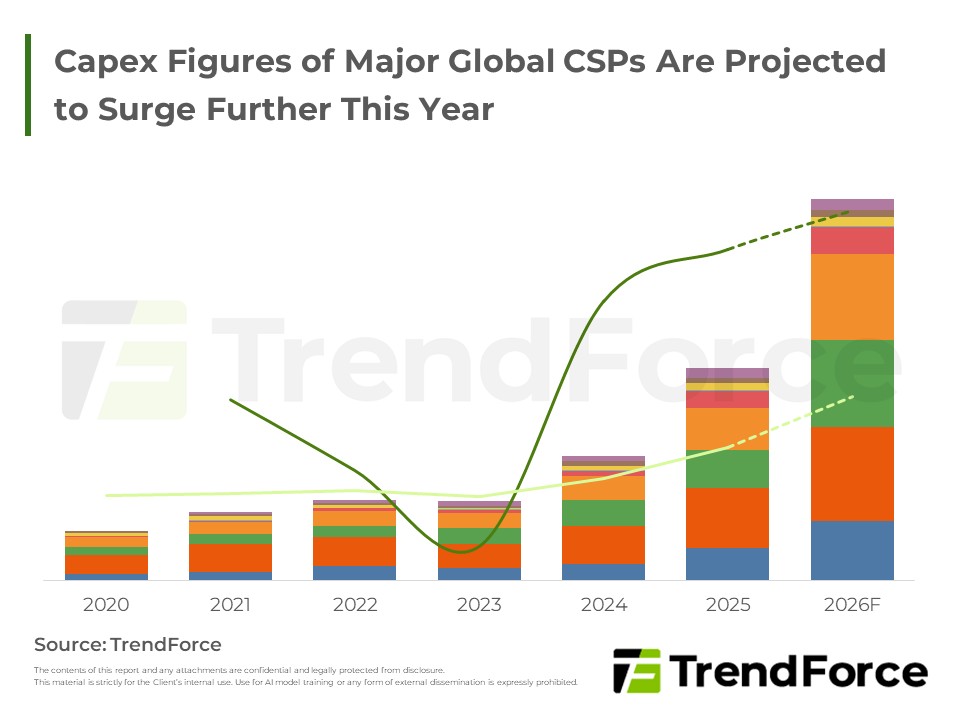
北美 CSP Capex 躍升,點燃 AI 伺服器與資料中心新動能
北美 CSP 於最新財報全面上修今年 Capex,反應 AI 基礎設施投資已成長期戰略核心,將持續推升全球 AI 伺服器與資料中心建置動能,並帶動液冷與 HVDC 等關鍵零組件需求顯著擴張。
獲取最新動態通用 GPU 架構的技術瓶頸
過往通用型的 GPU 依賴 HBM 與外部 DRAM 儲存模型權重,計算核心與記憶體分離,資料需頻繁在晶片與封裝間搬移,當推理流量呈現長期、連續成長,通用 GPU 架構的技術瓶頸逐漸浮現。
對以矩陣乘法為主的 Transformer 推理而言,記憶體頻寬與存取延遲是主要瓶頸。HBM 雖然提供高頻寬,但封裝複雜、良率與成本壓力並存,功耗亦隨頻寬提升而攀升。若推理任務多為低批次(Low Batch)、高即時性請求,GPU 難以大規模並行優勢攤提成本,導致效能利用率下降,能效比與單位 Token 成本成為真正的限制條件。
另一方面,由於模型規模不再是衡量競爭力的唯一指標,市場開始嘗試透過各式技術壓縮模型並維持其推理能力,例如 1.58-bit 量化技術與權重剪枝,使模型可在極低記憶體占用下維持推理準確度;MoE(混合專家)架構則透過「部分啟動」機制,在每次推理僅喚醒少數專家子網路,大幅降低實際運算量。
精簡模型的崛起,為硬體設計開創新的發展方向:當模型權重與結構趨於穩定,不再需要昂貴的動態記憶體支撐靈活性,將演算法直接編碼刻入晶片的技術便具備商業潛力。
硬式編碼推理晶片:功耗、散熱與資本效率具優勢
硬式編碼推理晶片因應效率瓶頸而生,Taalas 等廠商透過將模型權重固化於 Mask ROM,並以片上 SRAM 處理動態資料,大幅降低外部記憶體搬運功耗,顯著提升每瓦與每美元 Token 產出。最大效益為低延遲、低功耗與高吞吐,並可簡化散熱與封裝設計。
然而,市場對其最大疑慮在硬體缺乏彈性,難以應對快速迭代的模型更新。其次,彈性不足是其結構性風險,相較可程式化架構,專用晶片幾乎沒有調整空間,應用場景必須高度穩定且規模足夠,才能攤提高額 NRE(一次性工程費用,Non-Recurring Engineering)成本。再者,生態系亦是關鍵門檻,當前雲端市場仍依賴通用平台,客戶可能更偏好可隨模型升級的彈性解決方案。為降低風險,廠商透過自動化模型轉晶片流程、預製晶圓與混合可編程架構,並結合量化與 LoRA 微調設計,在「硬化」與「彈性」間取得折衷,使專用化得以商業落地。
未來硬式編碼技術預期將鎖定亞毫秒級反應與封閉場景,其模型結構穩定、隱私要求高與部署規模明確,硬式編碼晶片可在標準氣冷機櫃中運行,降低能耗與資本支出,對雲端服務商與垂直整合商尤具吸引力,對傳統依賴軟體編譯調度的 ASIC 廠商,則將遭遇性能挑戰。
TrendForce 預期通用 GPU 仍主導訓練與多模型環境,但在成熟、可預測場景中,其利潤空間將受到壓縮,產業格局因此從通用算力壟斷,走向通用與專用並行的雙軌結構。
Taalas HC1:硬式編碼推理的概念驗證
2026 年 2 月 20 日,加拿大 AI 晶片新創公司 Taalas 發佈 Taalas HC1,將 Meta 的開源 AI 模型 Llama 3.1 8B 模型直接刻印在晶片中,可以實現 16,960 tokens/s/user 的極高速率。
不僅如此,Taalas HC1 使用台積電 N6 製程,且不使用 HBM 記憶體、CoWoS 封裝,單一晶片功耗僅約 250 W,可採用氣冷散熱。因此,相較於 Nvidia B200(throughput optimized)運行 Llama 3.1 8B 的每百萬 tokens 成本為 3.79 cents,使用 Taalas HC1 的每百萬 tokens 成本僅為 0.75 cents,約為其五分之一。
圖 1. Taalas HC1 晶片:直接將 Llama 3.1 8B 模型 hard-wire 在晶片

來源:Taalas
圖 2. Taalas HC1 於 Llama 3.1 8B 模型之單用戶推理速率(tokens/s/user)
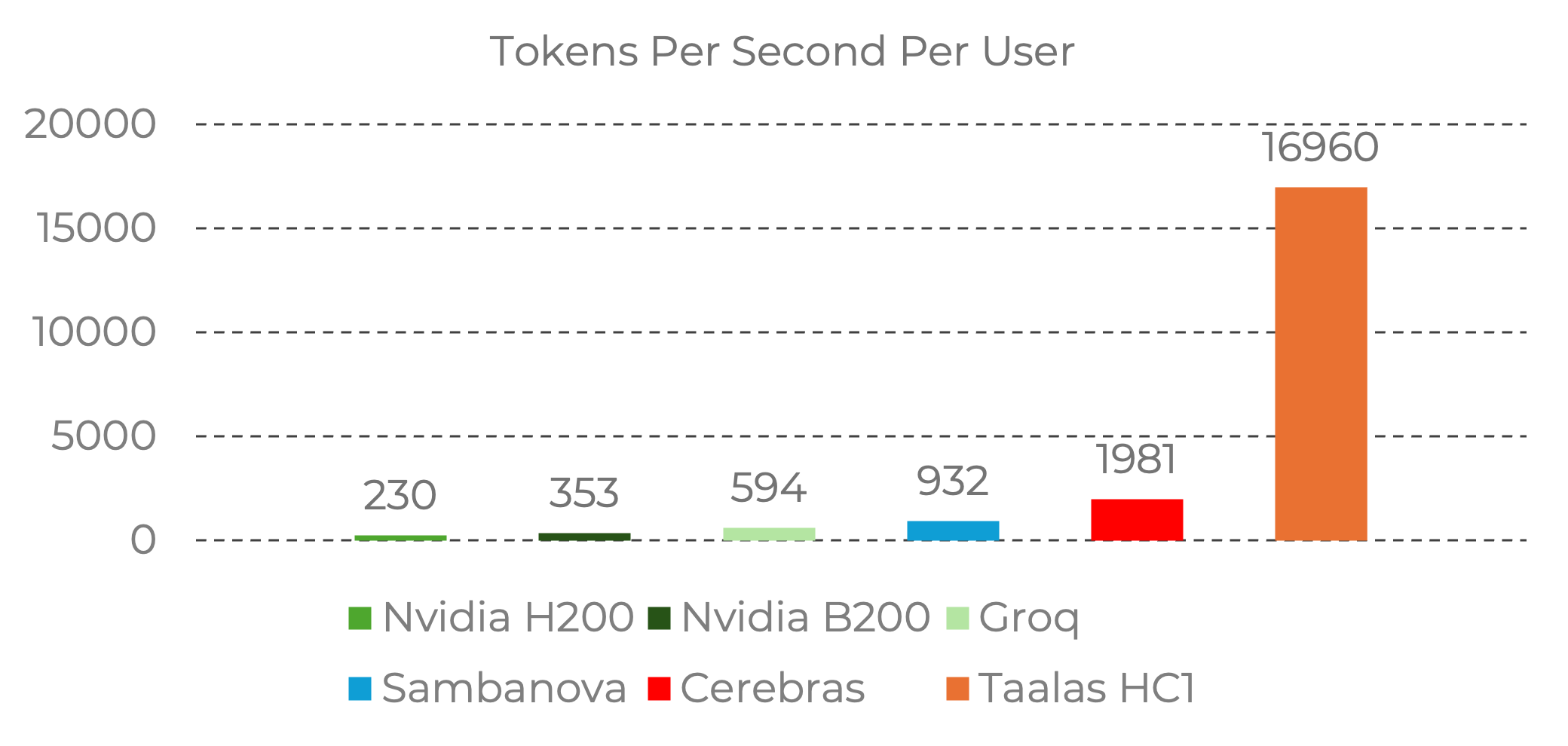
來源:Taalas
Taalas 的高效率歸功於採用記憶體內運算(Computing-in-Memory, CIM)的概念,也就是將運算功能整合至記憶體,達到「存算一體」,以消除資料在運算單元、記憶體之間頻繁傳輸的需求,去除記憶體牆的限制,即能降低運算時的多餘延遲及功耗。
記憶體內運算是什麼?
自 1945 年數學家 John von Neumann 發佈馮.諾依曼架構(von Neumann architecture)以來,晶片設計遵循運算器(Central Arithmetical, CA)、儲存單元(Memory, M)等組件分離的設計,以保留較大的靈活性。
隨著記憶體頻寬與算力成長逐漸不匹配,資料在運算單元、記憶體之間的傳輸成為瓶頸,記憶體內運算(Computing-in-Memory, CIM)便應運而生,目前已發展出數位 CIM(Digital CIM, DCIM)、類比 CIM(Analog CIM, ACIM)、混合 CIM(Hybrid CIM)等。不過,可以運行 CIM 的程式語言、軟體底層架構、應用程式皆尚未開發完全,技術仍在初期發展階段。
圖 3. CIM 三大技術類型:涵蓋 Digital CIM(DCIM)、Analog CIM(ACIM)與 Hybrid CIM 三種類型,並就其運作原理、精度與效率進行比較分析。

相較於一般 CIM 技術,Taalas 採取更激進的硬式編碼(hard-coded)做法。以「The model is The Computer」為開發理念,創造完全由硬體定義的 AI 硬體模型(hardcore model),將 AI 模型的權重直接刻印在晶片的 Mask ROM 中,在享有 CIM 技術的低延遲、低功耗的優點同時,也避開了 CIM 軟體生態系尚未成熟的瓶頸。
除了運算效率極高,由於使用高密度的 ROM 儲存模型權重,Taalas 僅需修改 2 層光罩就能產出另一個 AI 模型的專用晶片,將一個 AI 模型轉化為實體晶片僅需 2 個月。同時,Taalas 也保留一部分 SRAM 用於儲存 KV cache 和 LoRA 微調權重,彌補缺乏靈活性的缺點。
儘管實現方式不同,Taalas 的完全硬體定義技術與 Groq 的完全軟體定義技術目標一致,即盡可能達到靜態調度(static scheduling)、完全確定性(fully deterministic)的運算,藉由犧牲動態靈活性,換取最高效率。
多元並進的推理晶片新紀元
不僅 Taalas,專研高效率 Inference 應用的 AI 晶片新創公司陸續起步,像是 Tenstorrent、Groq、Cerebras、SambaNova、MatX、Untether AI、Hepzibah AI、Etched、d-matrix、Positron AI、Axelera AI、FuriosaAI 等。各廠晶片規格彙整如下圖:
圖 4. 高效能 AI Inference 晶片的技術架構與規格比較,技術類型涵蓋 CIM、SRAM-First、RISC-V 及晶圓級整合等
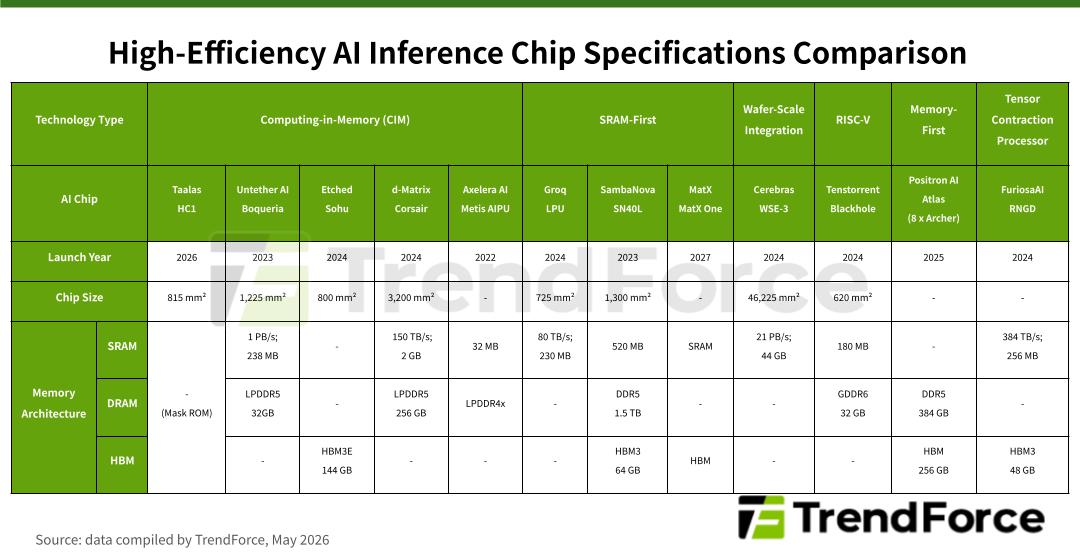
需注意的是,TrendForce 以 CIM 泛指廣義的存算一體架構,但各家實現方式不同。Taalas HC1 將模型權重直接固化於 Mask ROM(完全硬體定義);Etched Sohu 與 Taalas 同樣採 Hard-wired 架構,但適用所有 Transformer 模型,靈活性較高;d-Matrix Corsair 以數位記憶體內運算(Digital Computing-in-Memory, DIMC)為核心,將 AI 模型底層架構刻印在晶片中,適用所有 AI 模型,靈活性比 Etched 更大;Untether AI Boqueria 採 at-memory compute,將 RISC-V 處理器與處理單元直接整合進 SRAM memory bank 內部;Axelera AI Metis AIPU 同樣採數位記憶體內運算(Digital In-Memory Computing, D-IMC),並以 RISC-V 控制資訊流。
圖 5. d-Matrix Corsair 晶片架構
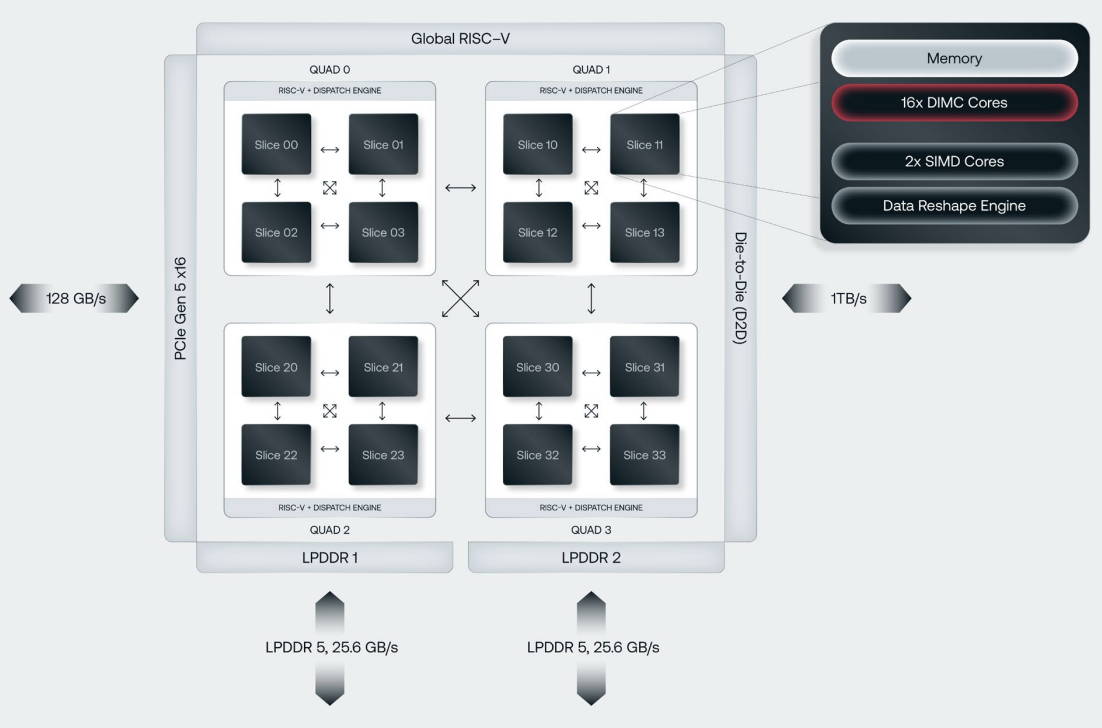
來源:d-Matrix
圖 6. Untether AI Boqueria 晶片架構
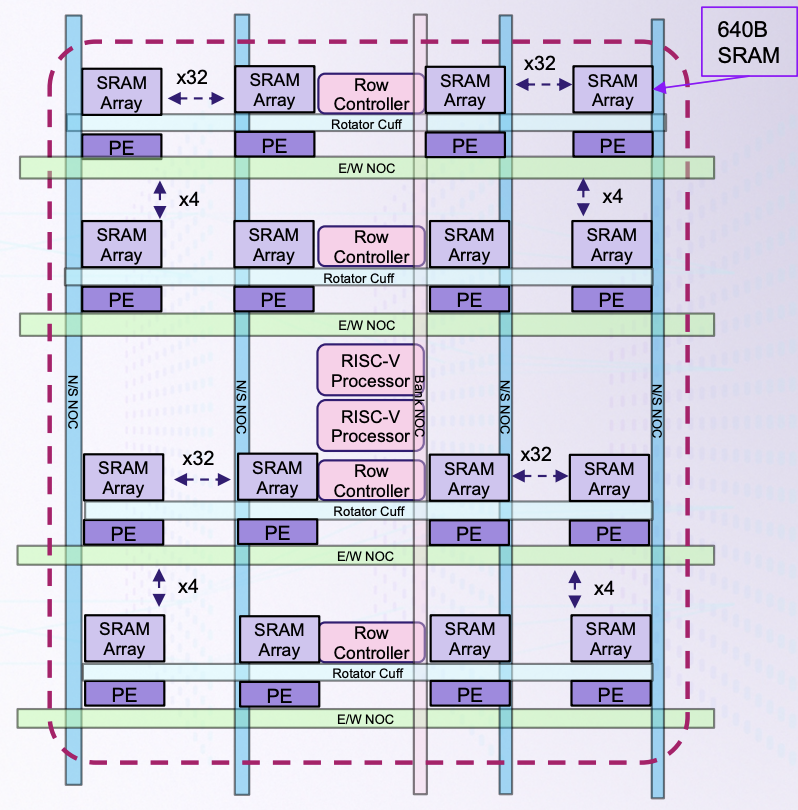
來源:Untether AI
另一方面,近期熱度最高的 Cerebras 於 2026 年 5 月 14 日在那斯達克掛牌上市。其核心技術為晶圓級整合(Wafer-Scale Integration, WSI),透過將整片 12 吋晶圓做成單一晶片(WSE-3),實現 44GB 片上 SRAM 與 21 PB/s 頻寬,並已與 OpenAI 簽訂逾 200 億美元、規模 750MW 的三年算力合作協議。
圖 7. Cerebras WSE-3 晶片架構

來源:Cerebras, TrendForce (2026/05)
目前,市場處於多線並進的早期探索期,各家新創同步嘗試不同的技術路線,像是記憶體內運算技術、以 SRAM 為主的架構、晶圓級整合、張量收縮等多元設計思維。預計未來 Inference 晶片架構將逐步融合各項技術,以符合 AI Inference 高速率、低功耗的運算需求。