2026 年的 AI 加速器市場,正處於一個關鍵的轉捩點。根據 TrendForce 的數據顯示,以 AI 伺服器總量的成長率來看,雲端服務商(CSP)自研的 ASIC 類別 2026 年成長率會來到 44.6%,大幅超越 GPU 的 16.1%。
圖 1
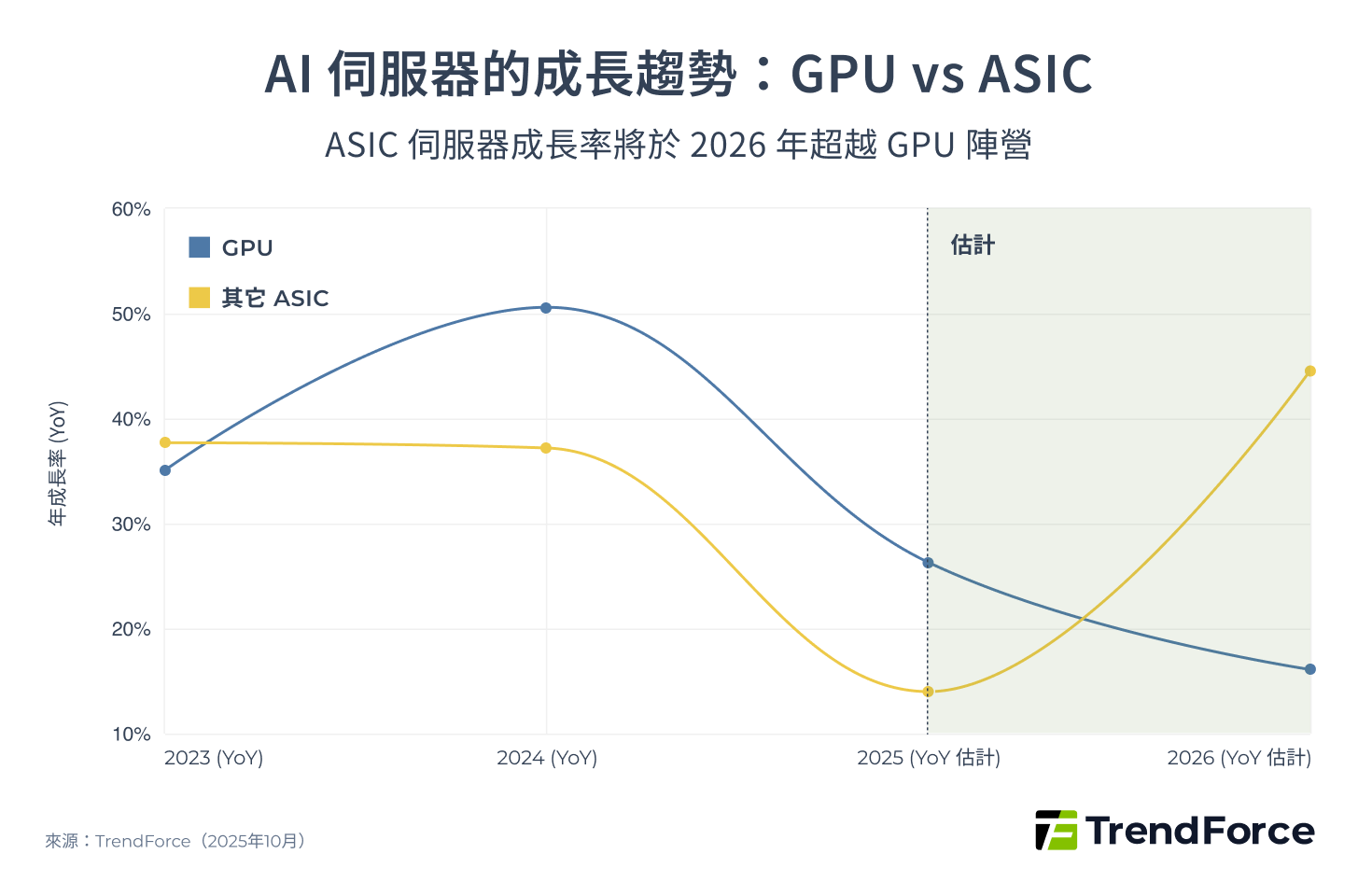
不過,這並不代表 NVIDIA 的主導地位會立即瓦解。相反地,這場戰役正在從單純的 GPU 性能競賽,轉變為一場更複雜、涉及互連網路與軟體生態的全方位戰爭。過去幾年 NVIDIA 「一路向上」的黃金時代,正迎來一個由多方勢力共同推動的平台期。
面對 ASIC 陣營以成本和效率發起的強勁挑戰,NVIDIA 的應對策略不再只是一味地提升單一晶片性能。他們近期動作頻頻,從技術路徑圖到產品架構,無不顯示出其深思熟慮的戰略轉變:
- NVIDIA 推出 NVLink Fusion:
宣布開放 NVLink 技術,允許客戶在自己的 ASIC 中使用,此舉不僅是技術的展示,更是意在打破自身生態系的封閉性,將其護城河從單純的硬體擴展至高速互連的軟體層面。 - NVIDIA 推出 Rubin CPX/VR200 NVL144 CPX:
專門針對大型語言模型(LLM)的 Inference(推論)應用,導入了全新的機架概念,並在 Rubin CPX 晶片間採用了 PCIe 6 互連。這項轉變尤其值得關注,它預示著 Inference 的 Prefill 和 Decode 階段將走向分離式架構,NVIDIA 藉此切入過去被視為較低階、但潛力巨大的 Inference 市場。 - NVIDIA 與 Intel 合作:
將 NVLink 的使用場景拓展至 x86 CPU,擴大其在伺服器互連領域的影響力。
NVIDIA 的營運策略與市場應對
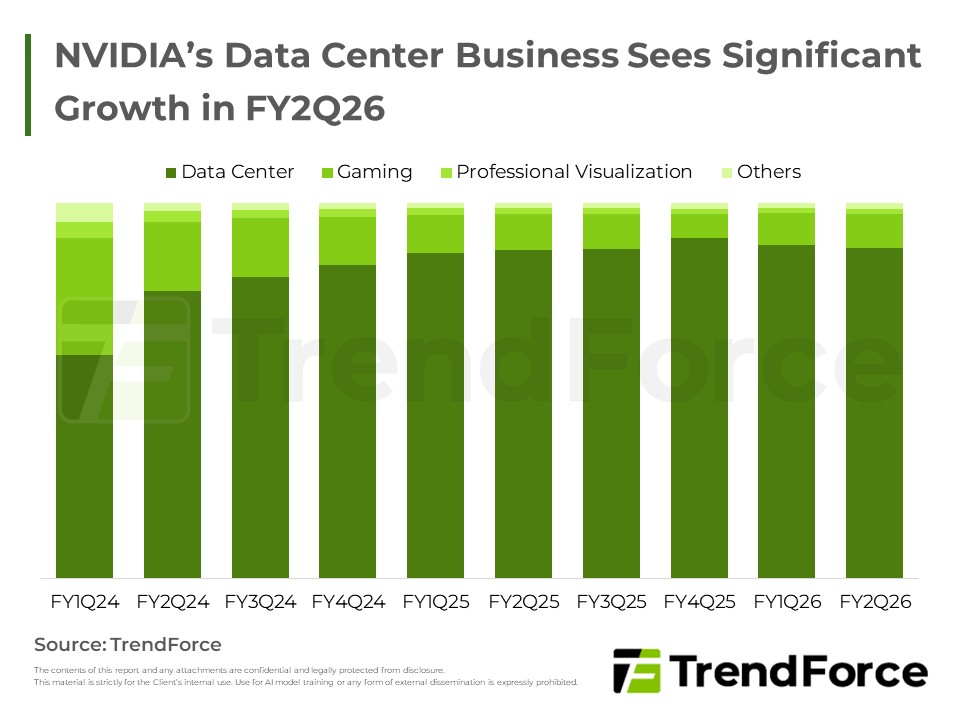
NVIDIA FY2Q26 資料中心營收占近 88%,GB Rack 預計將在 2H25 因 Oracle 需求顯著起量,但 H20 受中國政策影響,前景仍具不確定性。 了解趨勢 / Get Trend Intelligence
AI 資料中心的互連之戰
事實上,多個運算節點之間的整合已躍升為 AI 運算的關鍵驅動力,無論是目前為 AI 王者的 NVIDIA 還是 Broadcom 為首的 ASIC 陣營都認知到,資料中心互連網路是大規模 AI 擴展、跨節點協作與超級運算力的關鍵技術,已從配角躍升為決定勝負的核心,這也是為什麼兩大陣營在資料中心互連技術頻頻出招。
AI 基礎建設中的互連網路,根據傳輸頻寬、延遲、節點數和傳輸距離等技術要求,可分為三個層級:
- Scale-Up 定義為垂直擴展單一系統(如單一 Rack 或單一 SuperPOD)
- Scale-Out 定義為水平擴展多個系統(如約 4–16 個 SuperPOD 組成一個 Cluster)
- Scale-Across 定義為跨資料中心擴展
圖 2
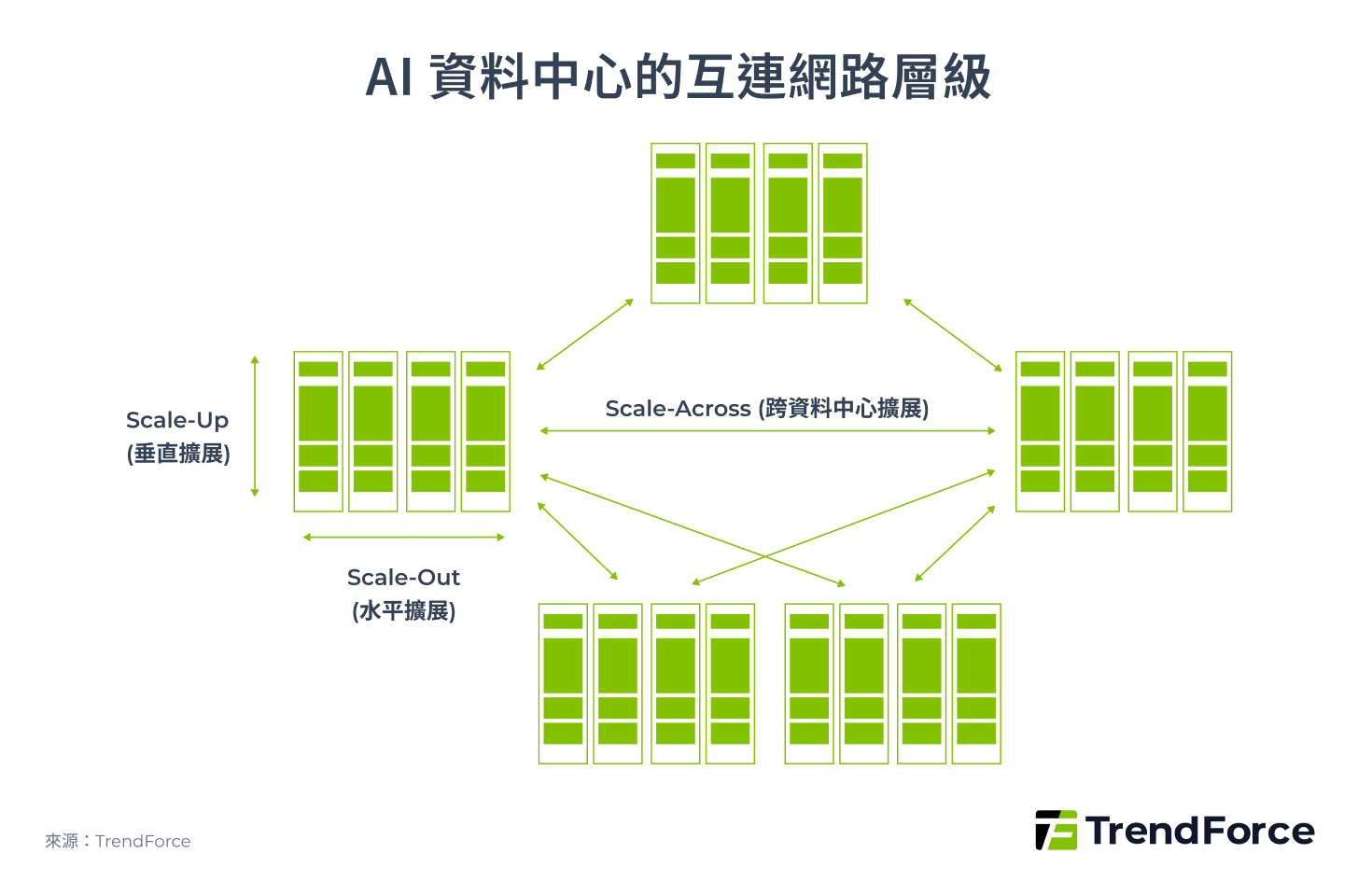
表 1. 資料中心的 Scale-Up、Scale-Out、Scale-Across 比較
| 層級 | Scale-Up | Scale-Out | Scale-Across |
|---|---|---|---|
| 定義 | 垂直擴展單一系統 (Rack / SuperPOD) | 水平擴展多個系統 (Cluster) | 跨資料中心擴展 |
| 現有協定 | NVLink、UALink、SUE、UB | InfiniBand、Ethernet、UE | Ethernet |
| XPU 頻寬 | ~ 8 Tbps | 400 / 800 Gbps | ~ 100 Gbps (E) |
| 延遲要求 | <1 μs | <10 ms | <20 ms (E) |
| 節點數 | <10k | 10-100k | 1-10M |
| 傳輸距離 | <500 m | 500 m - 10 km | <40 km |
| 拓樸 | Clos、3D Torus、Dragonfly+ | Clos、Dragonfly+ | Clos、Dragonfly+ |
| 硬體技術 | Rack(機櫃)內現以銅線為主,逐步轉向光纖 | 光纖 | 光纖 |
註: (E) 表示「估計」。
(來源:TrendForce)
網路拓樸與其結構改變對 Switch IC 需求量的影響
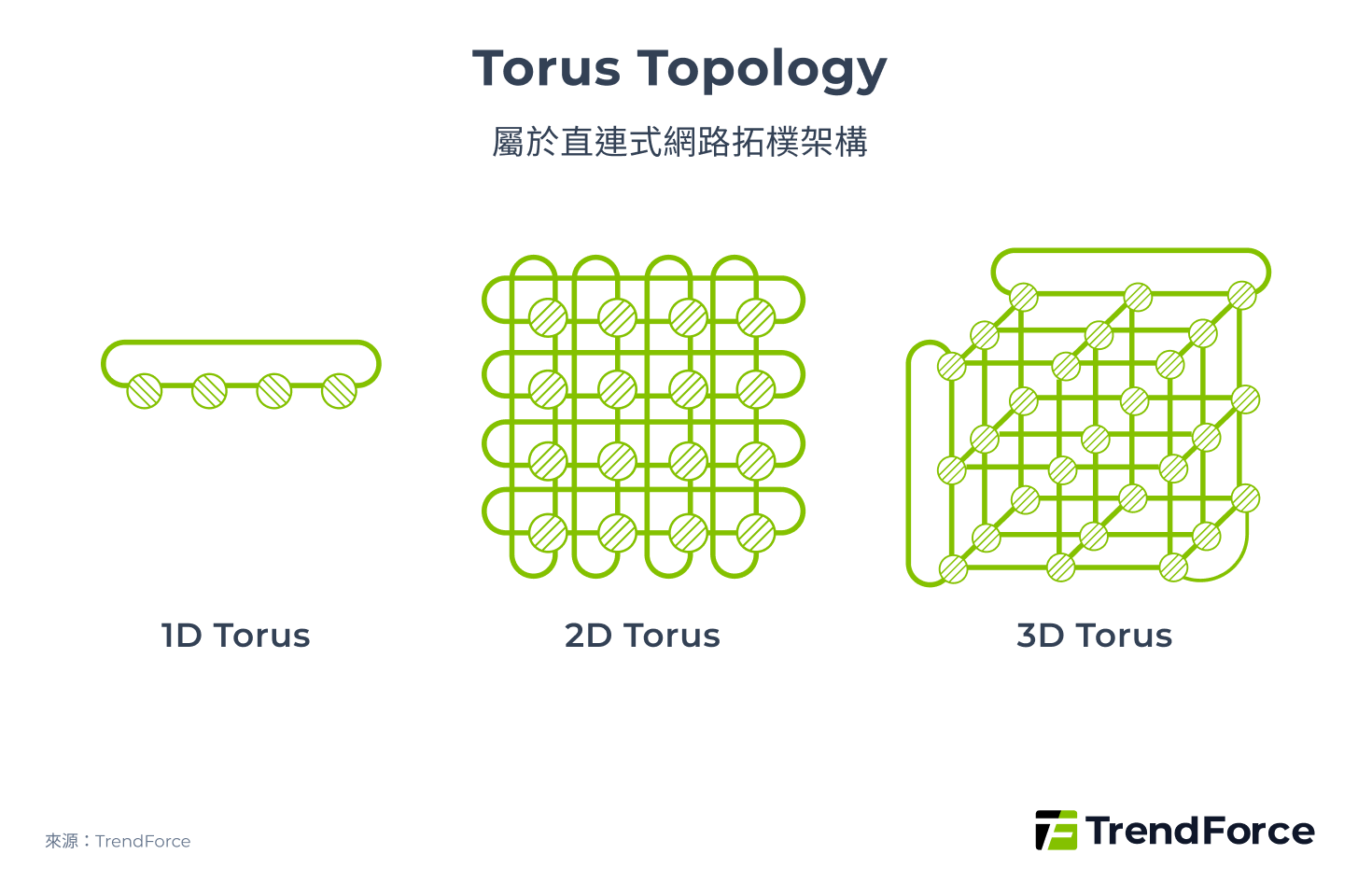
在網路架構中,運算節點間所連結的形狀即為拓樸(Topology),大致可分為階層式拓樸(Hierarchical Topology)、直連式拓樸(Direct-connect Topology)、混合式拓樸(Hybrid Topology)。而常見的網路拓樸包括 Clos、Torus、Fully Mesh,以及結合 Clos 和 Dragonfly 的 Dragonfly+。
表 2. 主要網路拓樸類別
| 連接類型 | Hierarchical | Direct-Connect | Hybrid |
|---|---|---|---|
| 定義 | 採用多層結構 | 節點之間直接互連 | 結合階層式與直連式 |
| 範例 | Clos | Torus、Full-Mesh、Dragonfly | Dragonfly+ |
| 圖例 | 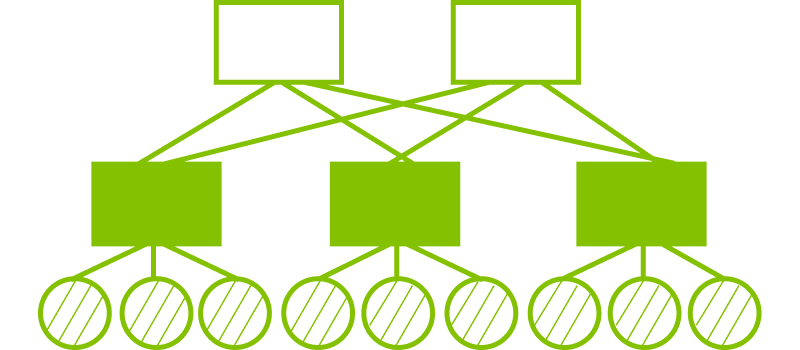 |
 |
 |
(來源:TrendForce)
網路拓樸的優劣可由六大指標評估:
- 性能(Performance)
- 彈性(Flexibility)
- 可模組性(Modularity)
- 可分割性(Divisibility)
- 成本效益(Cost-effectiveness)
- 對稱性(Symmetry)
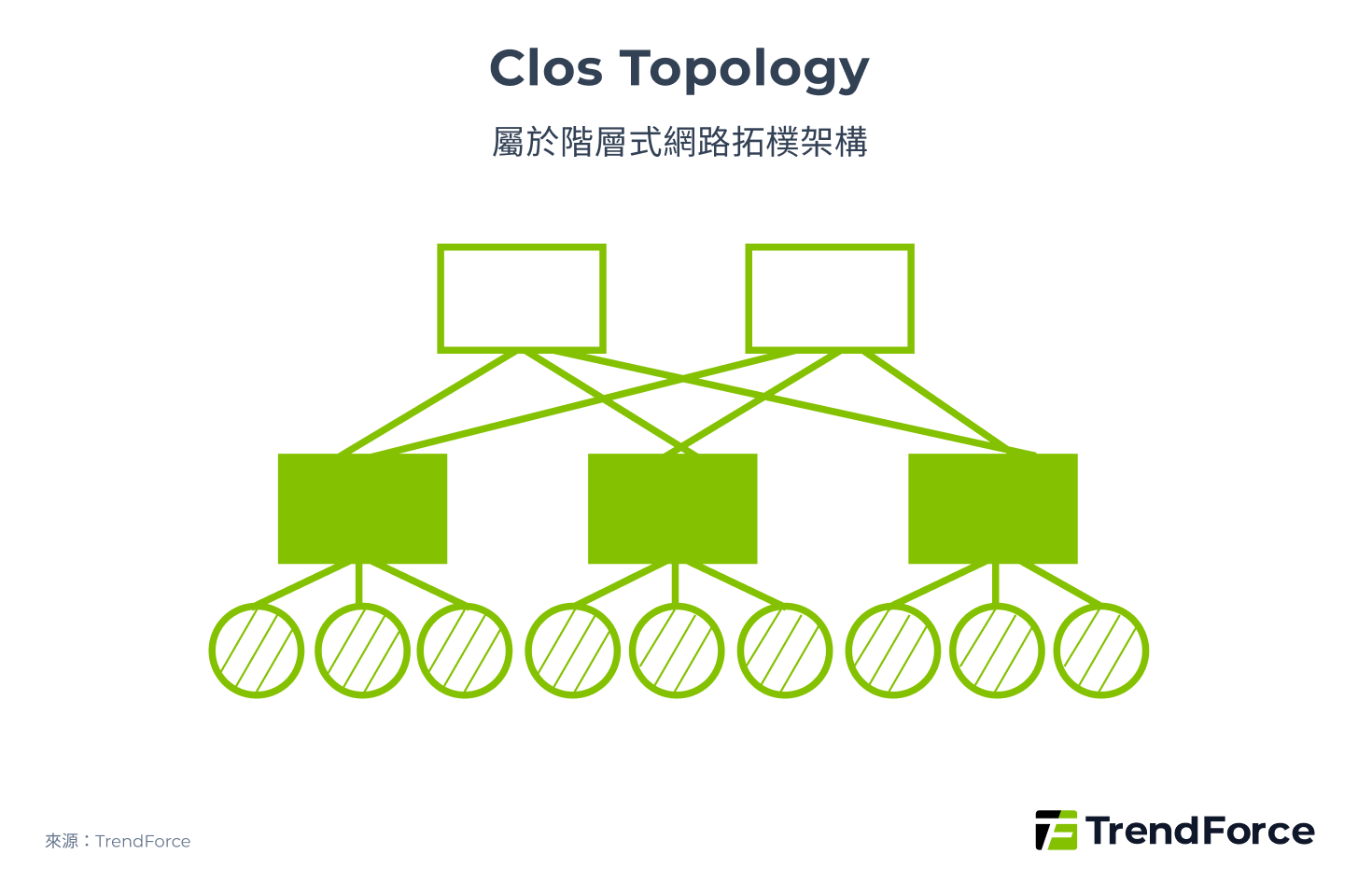
屬於階層式拓樸的 Clos(圖 3)技術最為成熟,在六大指標皆表現良好。該技術早在五十年前即運用於無阻塞電話網路,如今 2-Tier Clos(Leaf-Spine)架構也廣泛應用於資料中心,支援多種協定與晶片,如 Nvidia SuperPOD 之間的互連。但其缺點為可擴展性不如直連式拓樸。
圖 3
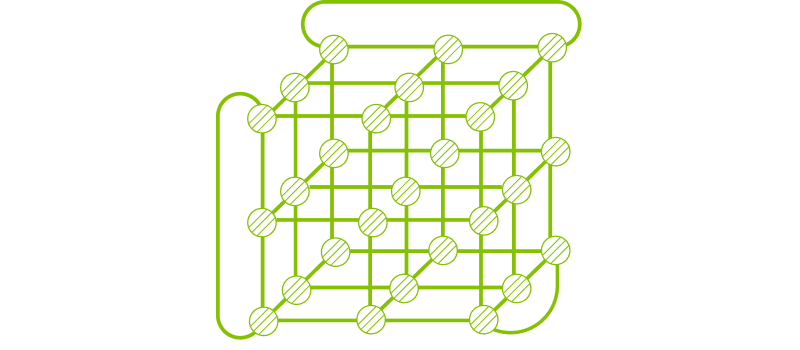
直連式拓樸方面,Torus(圖 4)具備優異的對稱性、可模組性、成本效益與彈性,因不需使用 switch,整體成本僅為 Clos 的 20% 以下。Google 目前的 ICI(Inter-Chip Interconnect)網路即採用 3D Torus 架構。然而,Torus 具有分割困難的問題,若擴大整體規模,使用拓樸中的一部分時效能將大幅下滑。例如,若單一 GPU 總頻寬 7,200 Gbps 直接與另外 7 顆 GPU 互連,單一連結頻寬將被拆分為 1,028 Gbps。
圖 4
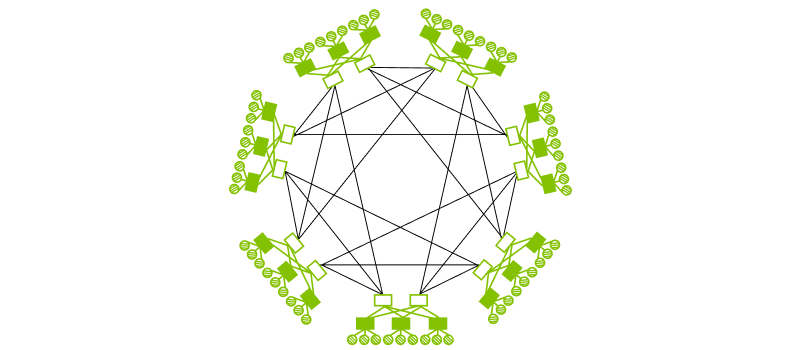
Full-Mesh(圖 5)使網路直徑隨規模擴大仍能保持恆定,讓其效能優於 Torus,然而仍具有分割困難、缺乏彈性等問題。實際應用如 Tesla 的 TTP(Tesla Transport Protocol)採用的 2D Full-Mesh。
圖 5

Dragonfly(圖 6)則是使多個 Switch 直接互連提升可擴展性,使擴展的成本效益優於 Clos,然而缺點為在局部性能不如 Clos。
圖 6

結合階層式拓樸、直連式拓樸優點的混合式拓樸應運而生,Nvidia 所使用的 Dragonfly+(圖 7)即為 Dragonfly、Clos 的混合體。在 Switch 組內採用 2-Tier Clos 以提升組內通訊效能,每對 GPU-GPU 間的互連頻寬不受 GPU 數量影響;在組間則採用 Dragonfly 的 1D Full-Mesh 網狀結構以提升擴展性。
圖 7
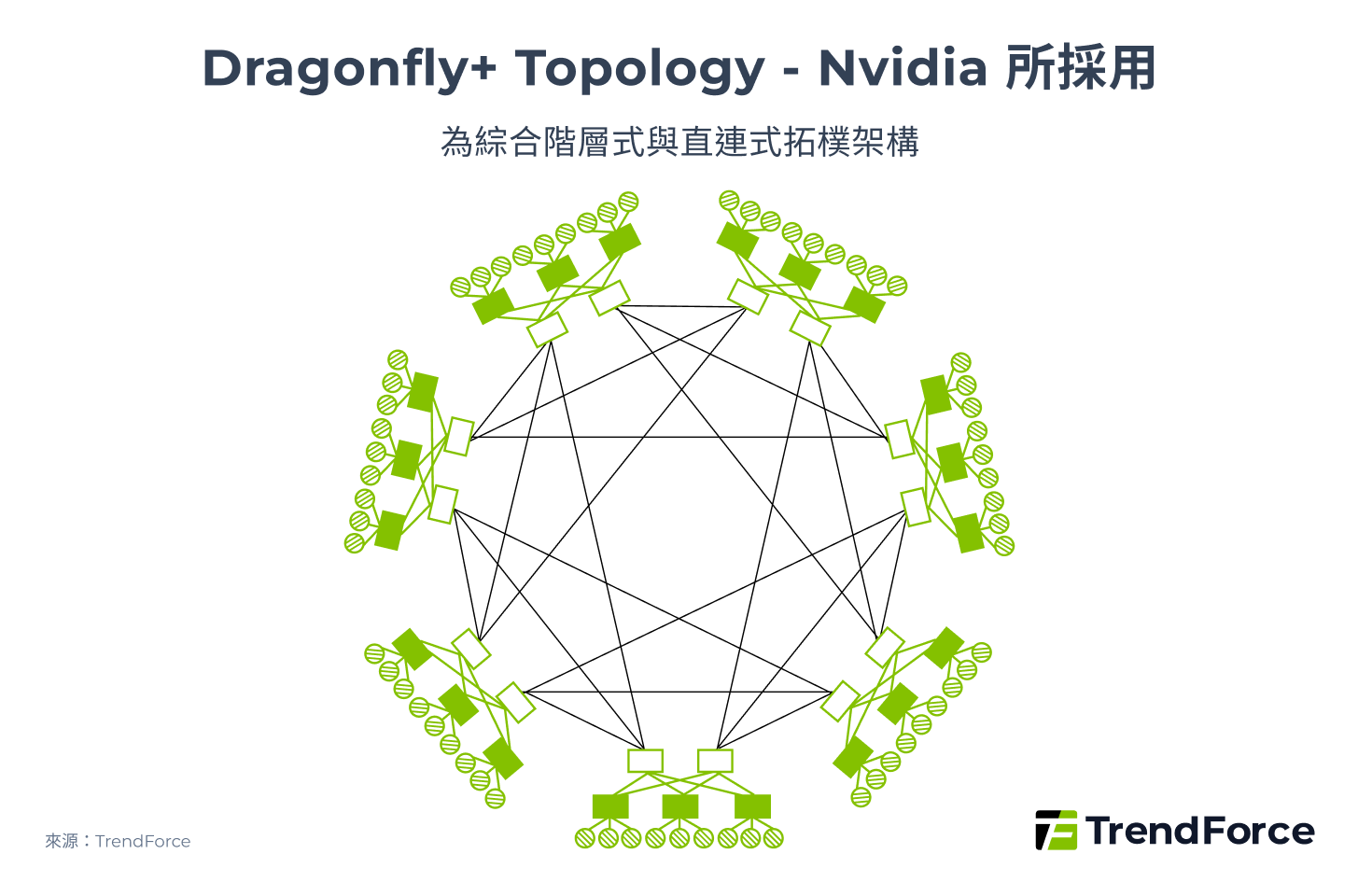
CSP 網路架構正走向混合式拓樸?
過去 CSP 所使用的 Scale-Up 網路多使用不需要 Switch 的 Torus、Mesh 拓樸,但隨著 SuperPOD 所連結的 XPU 數量規模愈來愈大,為了兼具效能、可擴展性、成本效益等優勢,預計未來 CSP 也將逐漸使用結合 Switch 的混合式拓樸,進而提升 Switch IC 的需求。
如 AWS 原先在 Trainium 2 使用的 Neuronlink 3 是使用 3D Torus,但在預計 4Q25 推出的 Trainium 2.5 Teton PDS 中,將改為需要 Switch IC 的混合式拓樸,採用 Astera Labs 基於 Scorpio-X 的客製化 Switch IC。
圖 8
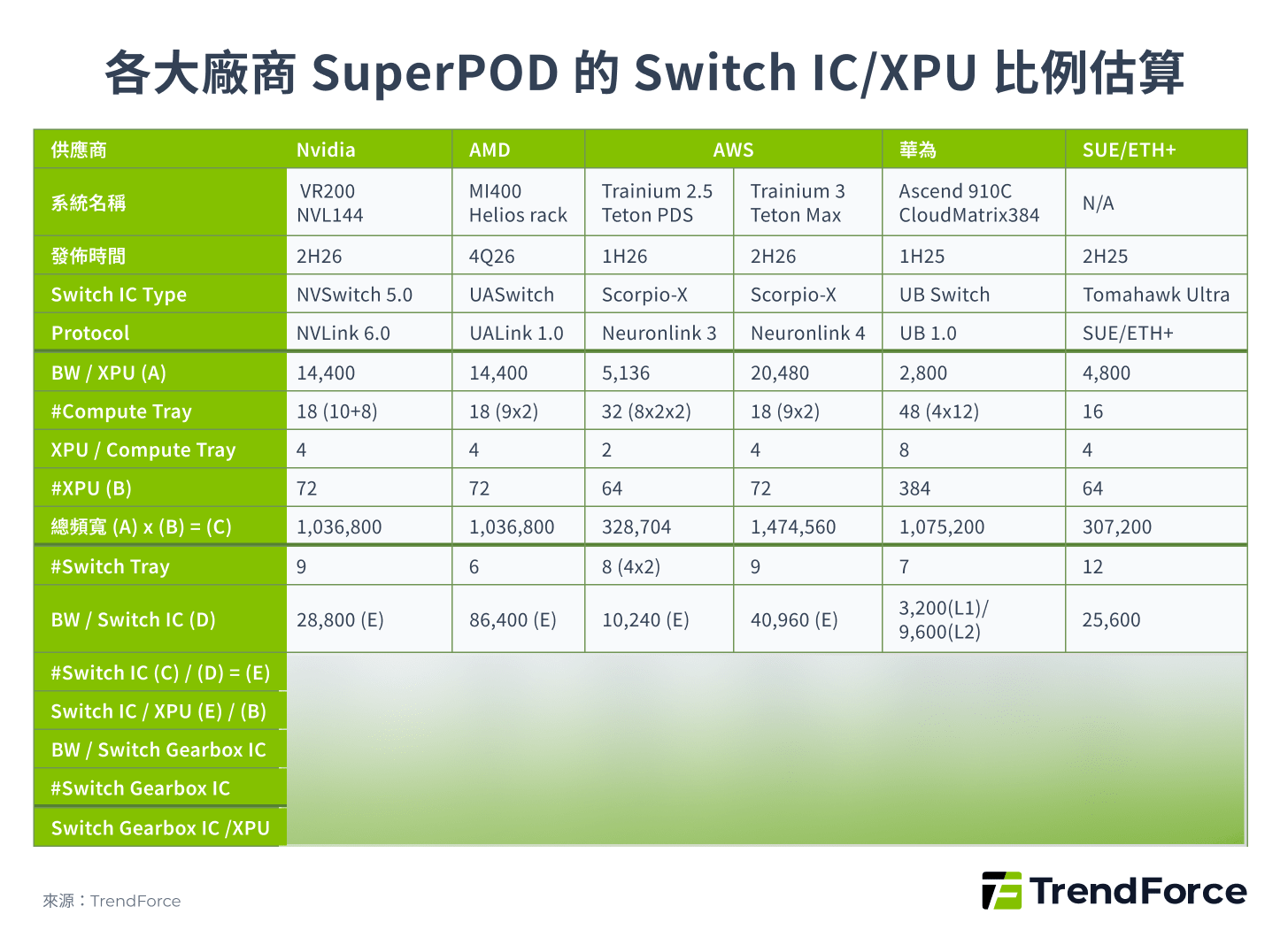
Scale-Up 競爭格局:NVIDIA 的護城河與挑戰者
NVIDIA 憑藉其 NVLink 技術,在 Scale-Up 市場建立了難以撼動的領先地位。其技術路徑圖清晰可見:從 2014 年的 NVLink 1.0 到 2024 年的 NVLink 5.0,單一 GPU 的雙向總頻寬從 160 Gbps 躍升至 1,800 Gbps。
NVIDIA 的 NVSwitch 技術也隨之進化,從最初實現 16 顆 GPU 的全互連,到 NVL576 機櫃實現 576 顆 GPU 的高速連接,其在技術規格上領先對手約一年。
值得注意的是,NVIDIA 的戰略正在從單純的技術規格領先,轉向更全面的生態系防禦:
- 技術規格的穩步推進:從 2014 年的 NVLink 1.0 開始,NVIDIA 幾乎每兩年發布一次新版本,持續提升單一 GPU 的頻寬和節點數。
- 調變技術的革新:從最初的 NRZ 轉向 PAM4,實現傳輸速率翻倍,這顯示其在底層物理技術上亦持續投入。
- 產品架構的多元化:除了傳統的 DGX 系列,NVIDIA 透過 GB200 NVL72、VR200 NVL144 CPX 等產品,提供更多元、更具針對性的機櫃解決方案。
表 3. NVLink 技術演進
| 推出時間 | 2014 | 2017 | 2018 | 2020 | 2022 | 2024 | 2025 | 2026 | 2027 |
|---|---|---|---|---|---|---|---|---|---|
| GPU 類型 | P100 | V100 | A100 | GH100 | GH100 | GB200 | GB300 | VR200 | VR300 |
| DGX 型號 | DGX-1 | DGX-1 | DGX-2 | DGX A100 |
DGX H100
NVL32
|
NVL72 | NVL144 | NVL144 | NVL576 |
| NVLink | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | 6.0 | 7.0 | ||
| GPU per DGX | 8 | 8 | 16 | 8 |
8
32
|
72 | 72 | 144 | |
| NVSwitch | N/A | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | 6.0 | ||
| Lane per Port | 8 | 4 | 2 | 2 | 4 (E) | 4 (E) | |||
| BW/Lane | 20 Gbps | 25 Gbps | 50 Gbps | 100 Gbps | 200 Gbps | 200 Gbps (E) | 400 Gbps (E) | ||
| Modulation | NRZ | NRZ | NRZ | PAM4 | PAM4 | PAM4/PAM6 (E) | |||
| Structure | Cube Mesh | All-to-All | |||||||
註: (E) 表示「估計」。
(來源:TrendForce)
然而,這條護城河並非無懈可擊。各大 CSP 和晶片供應商正積極開發各自的 Scale-Up 技術,試圖降低對 NVIDIA 的依賴。AMD 的 UALink、Broadcom 的 SUE、AWS 和 Google 的自研技術,都旨在提供更開放或封閉的替代方案。
NVIDIA NVLink Fusion 打破封閉,創造新生態
NVIDIA 的 NVLink Fusion 策略,是其對抗 ASIC 陣營的關鍵一步。透過將 NVLink 介面開放為 I/O IP,NVIDIA 允許客戶將其整合至自己的 ASIC 或 CPU 中。這不僅使得客戶能夠享受到 NVLink 的高速傳輸,更重要的是,他們同時也將被鎖定在 NVIDIA 廣泛的軟體工具鏈中。
這是一個巧妙的「以退為進」策略,NVIDIA 讓出硬體層的部分市場,換取在軟體和生態系層面更深層次的控制權。Fujitsu 和 Qualcomm 已率先將其導入自家 CPU 設計中,這也證明了這一策略的有效性。
中國戰場:本土 Scale-Up 巨頭的崛起
在 AI 算力競賽中,中國市場已形成一套獨立於 NVIDIA 生態之外的競爭格局。 除了 CSP 自研 ASIC 的通用趨勢外,本土的技術巨頭,尤其是華為,正在 Scale-Up 領域建立起自己的生態系統,對 NVIDIA 的市場主導地位構成直接挑戰。
目前,中國主要的自研 Scale-Up 技術標準包括:
- 華為的靈衢(Unified Bus, UB): 領先的封閉式解決方案,正在轉向開放。
- 阿里巴巴主導的 ALS(Alink System): 一個由阿里的雲端部門與 AMD 共同推動的開放聯盟。
- 騰訊主導的 ETH-X: 一個專注於優化乙太網(Ethernet)效能的開放標準。

2025 全球及中國 AI 資料中心佈局與展望
美系業者持續全球部署,並加大對美投資;中國業者除了維持在地化,也透過自研晶片外擴全球,雙方的未來都將能源穩定性擺在首要位置。 了解趨勢
華為 UB 的技術力與市場野心
華為的 UB 協議是中國市場中技術最成熟、部署規模最大的 Scale-Up 解決方案。2025 年,華為基於 UB 1.0 發布了 Atlas 900 A3 SuperPOD,其核心亮點在於規模與互連效率。
這套系統實現了 384 顆昇騰 910C NPU 的高速互連,單通道頻寬高達 400 Gbps。值得注意的是,其 CloudMatrix384 架構採用了 2D-Full Mesh 混合式設計,這意味著它在單一板卡層級和單一機架層級都實現了高密度的互連,而非單純的線路堆疊。
圖 9
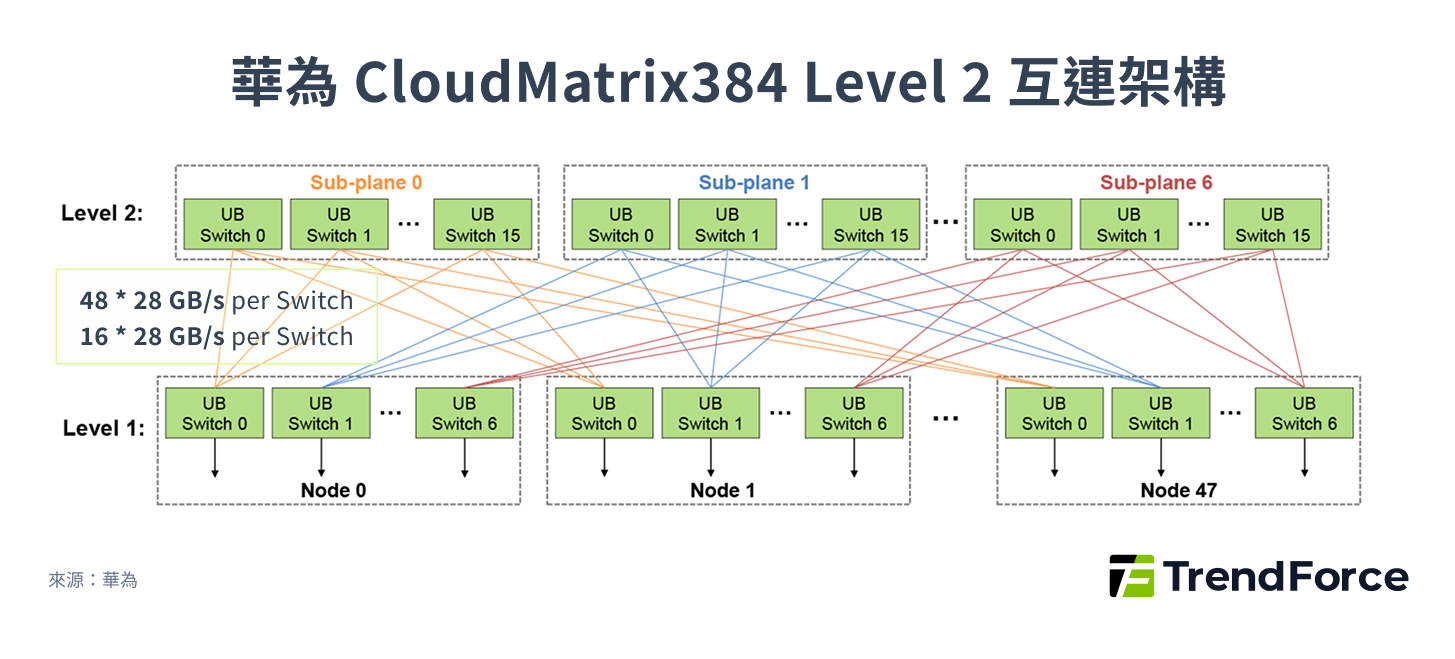
更具戰略意義的是,華為預計在 2026 年推出的 Atlas 950 SuperPOD,將採用下一代 UB 2.0 協議,目標是實現 8,192 顆 NPU 的龐大規模互連。
這一數字不僅遠超當前市場主流部署,更透露出華為在超大規模模型訓練市場的勃勃野心。
同時,華為宣佈 UB 2.0 將對外開放,這一舉動與 NVIDIA 的 NVLink Fusion 策略異曲同工,旨在將其技術標準化,並藉此擴大其生態影響力,跨入其他 XPU 的市場。
中國開放標準推動 Scale-Up 市場發展
除了華為的封閉轉開放策略,中國市場也積極發展多個開放標準,以降低對單一供應商的依賴。
- ALS:由阿里巴巴和 AMD 主導,聯盟成員涵蓋 Broadcom 和 Intel 等十多家公司。這套標準與 AMD 的 UALink 協定有異曲同工之妙,旨在透過開放的聯盟模式,推動 Scale-Up 領域的多元化競爭。
- ETH-X:由騰訊主導,聯盟成員多達三十多家。該標準專注於改良 Ethernet 架構,並結合 RoCE 技術來提升頻寬。與 ALS 不同,ETH-X 的技術核心在於透過調整傳輸編碼方式來提升傳輸效率,這在提供高頻寬的同時,也可能導致更高的運算複雜度和延遲。這與 Broadcom 主導的 SUE(Scale-Up Ethernet)協定有相似之處。
表 4. NVLink 與中國 Scale-Up 技術比較
| 技術 | NVLink 5.0 | UB 1.0 | ALS | ETH-X |
|---|---|---|---|---|
| 推出時間 | 2024 | 2Q25 | 4Q24 | 4Q25 |
| 主導者 | NVIDIA | 華為 | 阿里巴巴 | 騰訊 |
| 拓樸 | Clos | Clos | Clos | Clos |
| 雙向頻寬 / port | 800 Gbps | 800 Gbps | 800 Gbps (UALink) | 800 Gbps |
| 節點數 | 576 | 384 | 1,024 (UALink) | 64 |
| 延遲 | <1 μs | <2 μs | <1 μs | <1 μs |
| 生態系 | 封閉(NVLink Fusion 推出前) | 封閉(UB 2.0轉為開放) | 開放 | 開放 |
(來源:TrendForce)
從性能之爭到生態系之戰,AI 晶片戰的終極戰場
綜觀這場圍繞 AI 加速器的戰役,我們看到一個清晰的趨勢:單純的硬體性能競賽,已不再是唯一的決勝點。
從 NVIDIA 近期推出 NVLink Fusion 讓客戶在其自有 ASIC 中使用 NVLink,到中國華為宣布將其 UB 2.0 協議對外開放,這些舉動都證明,AI 晶片巨頭們正將戰場從硬體規格的軍備競賽,轉向更深層次的生態系與軟體護城河之戰。
NVIDIA 深知,雖然其 GPU 仍主導著高端訓練市場,但若要維持其 AI 王座的地位,必須透過其無可匹敵的 CUDA 生態系,將客戶更深地鎖定在其技術架構中。這種「以退為進」的策略,是讓出部分硬體控制權,換取在軟體和工具鏈層面更廣泛的影響力。
與此同時,以 Broadcom 為首的 ASIC 陣營,也正透過推動開放標準,為 CSPs 提供擺脫單一供應商限制的替代方案。華為、阿里巴巴等中國巨頭,則積極在國內市場建立獨立的生態系,試圖複製 NVIDIA 的成功模式。
未來的市場主導者,將是那些能夠提供最完善、最易用的軟硬體整合方案的玩家。這場戰役將不再由單一晶片的性能來定義,而是由生態系的廣度、深度和黏著度來決定。