隨著 AI 模型規模爆炸性增長,資料中心擴展已從單一系統的 Scale-Up 進入數萬節點互連的 Scale-Out 階段。Scale-Out 網路主要由兩大技術陣營競爭:
- InfiniBand:作為性能王者,由 NVIDIA 旗下 Mellanox 所主導,憑藉原生 RDMA 協定,提供 <2us 的極低延遲和無丟包風險。
- Ethernet(乙太網路):具有開放生態與顯著的成本優勢,由 Broadcom 等大廠推動。
2025 年 6 月,Ethernet 發起強勢反擊,超乙太網路聯盟(UEC)發佈 UEC 1.0,透過重構網路層級,實現媲美 InfiniBand 的極致效能,多重優勢下估計 Ethernet 將逐漸擴大市場規模,這場技術變革重塑了整個 Scale-Out 市場競爭格局!
圖 1
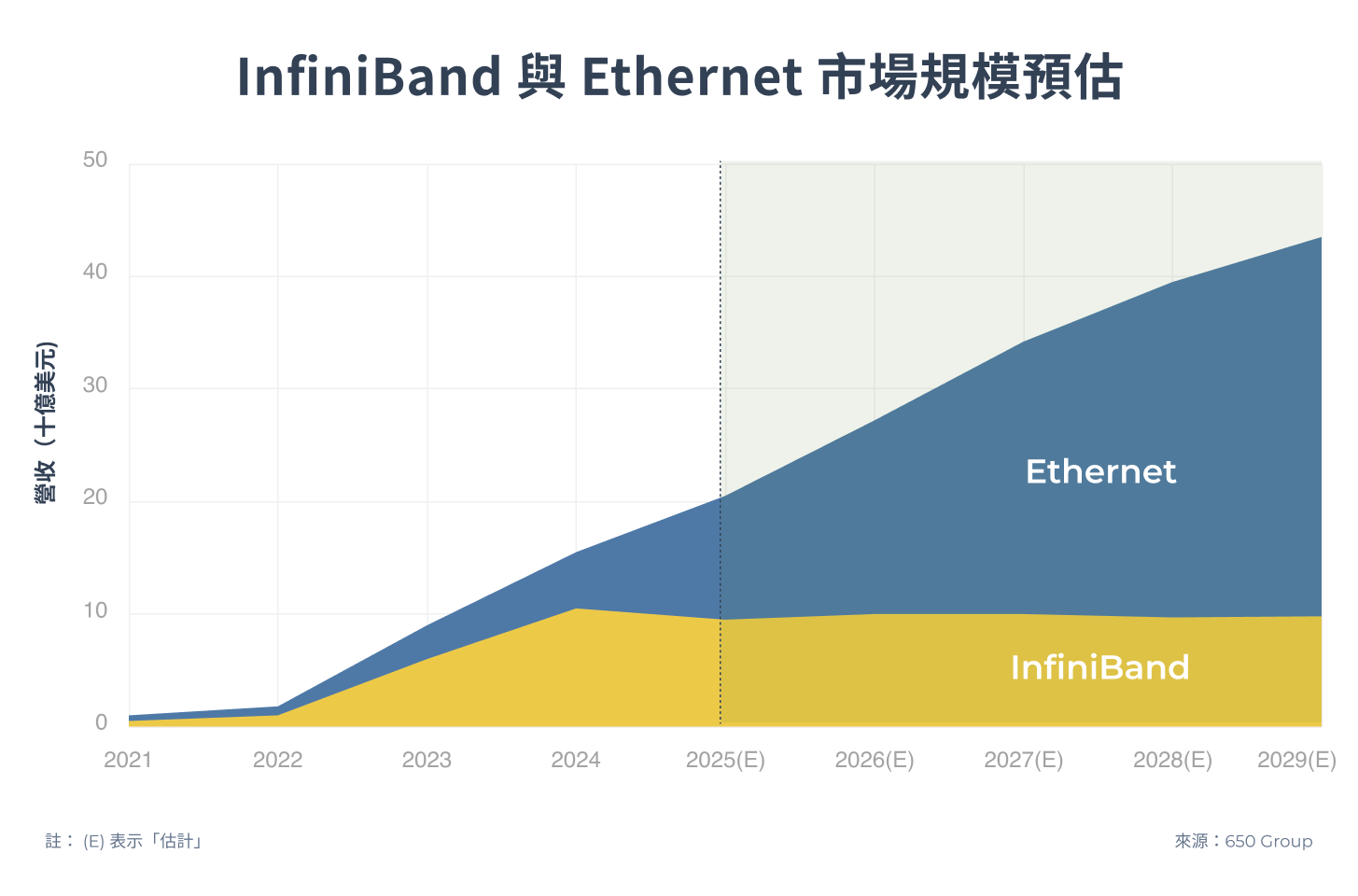
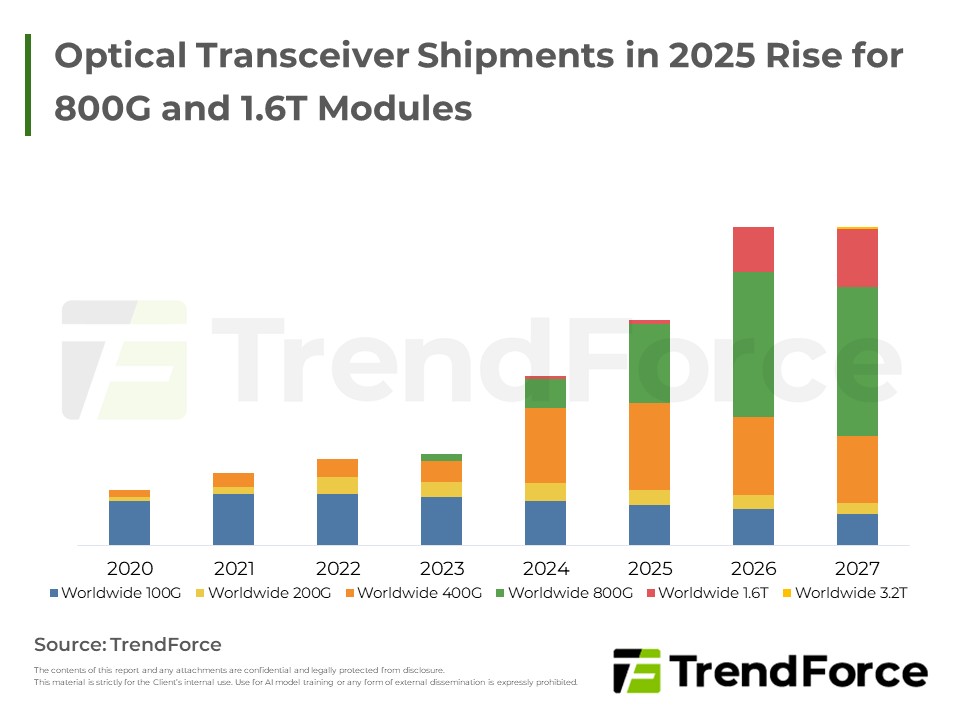
Scale-Out 關鍵戰場:InfiniBand 優勢與 Ethernet 反擊
目前 Scale-Out 主流的 InfiniBand 架構,擁有原生的遠端直接記憶體存取(Remote Direct Memory Access, RDMA)協定,其原理為:
- 資料傳輸時透過 DMA 控制器傳送到具 RDMA 功能的網路介面卡(RNIC)。
- 由 RNIC 進行資料包封裝後,直接傳送到接收方的 RNIC。
由於過程中不需要如傳統 TCP/IP 協定須經過 CPU 參與,因此 InfiniBand 資料傳輸便可達到極低延遲(<2 μs)。
此外,InfiniBand 還擁有在連結層(Link Layer)的基於信用的流量控制(Credit-Based Flow Control,CBFC)機制,確認接收方有可用空間才傳輸資料,確保零丟包風險。
原生的 RDMA 協定需要搭配 InfiniBand 交換器(Switch)才能運作,然而,InfiniBand Switch 長期被 NVIDIA 旗下的 Mellanox 所主導,生態系相對封閉,且採購、維運成本較高,硬體成本約為 Ethernet Switch 的 3 倍!
表 1. InfiniBand 技術演進
| 年份 | 2011 | 2015 | 2017 | 2021 | 2024 | 2027 | 2030 |
|---|---|---|---|---|---|---|---|
| 資料速率 | FDR (Fourteen Data Rate) |
EDR (Enhanced Data Rate) |
HDR (High Data Rate) |
NDR (Next Data Rate) |
XDR (eXtreme Data Rate) |
GDR (E) | LDR (E) |
| 頻寬/Port (8 Lanes) | 109 Gbps | 200 Gbps | 400 Gbps | 800 Gbps | 1.6 Tbps | 3.2 Tbps | 6.4 Tbps |
| 頻寬/Port (4 Lanes) | 54.5 Gbps | 100 Gbps | 200 Gbps | 400 Gbps | 800 Gbps | 1.6 Tbps | 3.2 Tbps |
| 頻寬/Lane | 13.6 Gbps | 25 Gbps | 50 Gbps | 100 Gbps | 200 Gbps | 400 Gbps | 800 Gbps |
| 調變技術 | NRZ | NRZ | NRZ | PAM4 | PAM4 | PAM6 (E) | PAM6 (E) |
註: (E) 表示「估計」。
(來源:TrendForce)
因為 Ethernet 擁有開放生態系、多家供應商、部署靈活、硬體成本較低,使其逐漸興起。
為了在 Ethernet 上也能實現 RDMA 的優點,IBTA(InfiniBand Trade Association)於 2010 年推出了基於融合乙太網路的 RDMA:RoCE(RDMA over Converged Ethernet)協定。初始的 RoCE v1 僅在 Link Layer 加入 Ethernet Header,受限於 Layer 2 子網路內通訊,無法跨路由器或不同子網傳輸。
為提升部署靈活性,IBTA 於 2014 年推出 RoCE v2,將 Layer 3 Network Layer 中的 InfiniBand GRH(Global Route Header)修改為 IP/UDP Header,此改動使 RoCE 封包能被標準 Ethernet Switch 與路由器識別和轉發,就能跨越多個子網或路由器傳送,部署靈活性大幅提高。然而,RoCE v2 的延遲仍略高於原生 RDMA 約 5 μs,且需要額外功能(如 PFC、ECN)以降低丟包風險。
圖 2
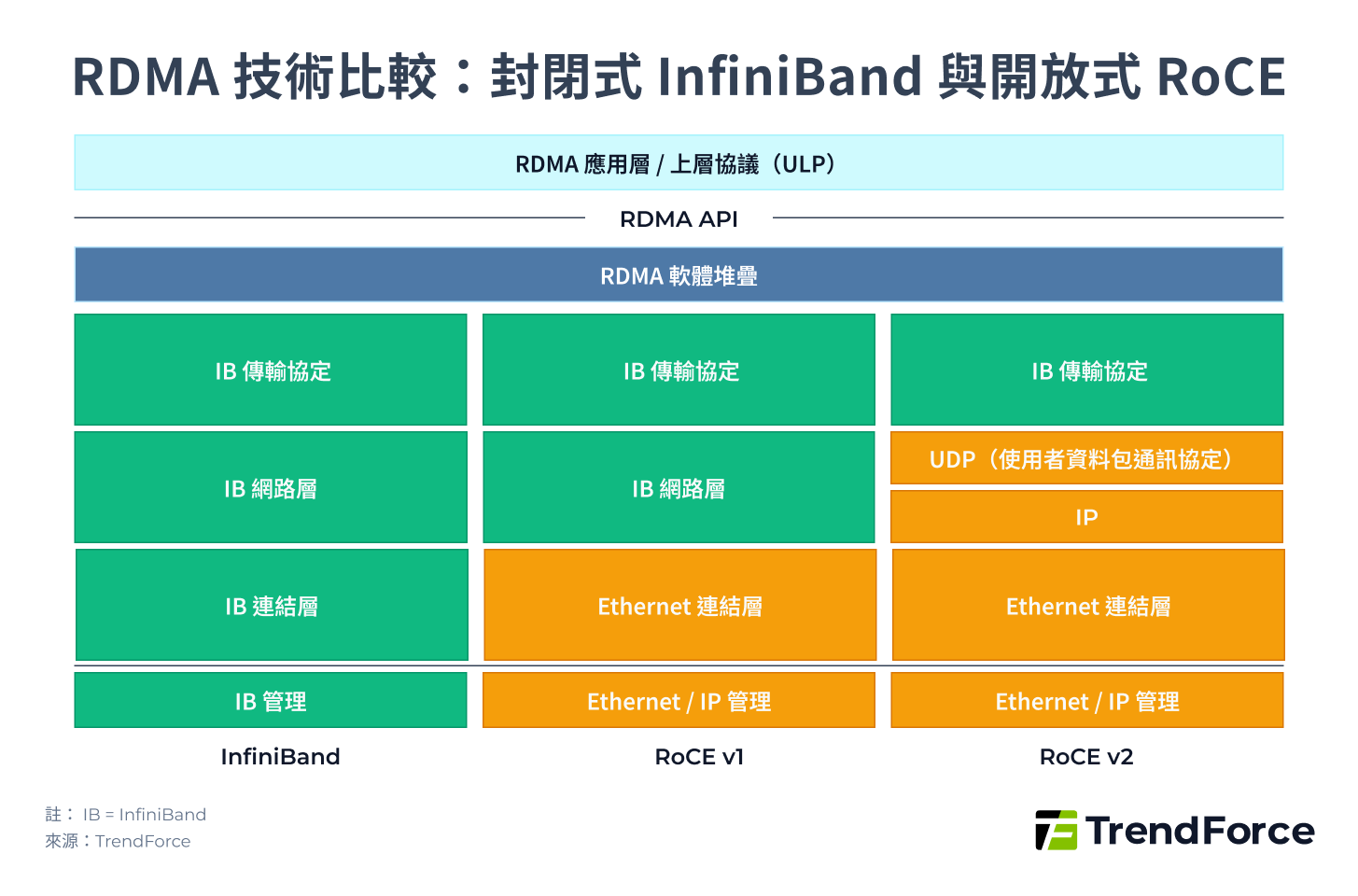
上圖 2,RDMA 技術下的 InfiniBand 與開放式 RoCE 比較重點:
- InfiniBand 為封閉協議堆疊,全棧自有,延遲最低。
- RoCE v1 在 Ethernet 下模擬 IB 架構,只能在同一 Layer 2 網段使用。
- RoCE v2 採 IP 網路層,支援跨網段,與現有資料中心的 Ethernet 架構相容性最高。
表 2. Ethernet 技術演進
| 年份 | 2016 | 2018 | 2019 | 2021 | 2023 | 2025 | 2027 |
|---|---|---|---|---|---|---|---|
| 單晶片總頻寬 | 3.2 Tbps | 6.4 Tbps | 12.8 Tbps | 25.6 Tbps | 51.2 Tbps | 102.4 Tbps | 204.8 Tbps |
| 單晶片 Port 數 | 32 | 64 | 64 | 64 | 64 | 64 | 64 |
| 頻寬/Port | 100 Gbps | 100 Gbps | 200 Gbps | 400 Gbps | 800 Gbps | 1.6 Tbps | 3.2 Tbps |
| Lane數/Port | 4 | 4 | 4 | 4 | 8 | 8 | 8 |
| 頻寬/Lane | 25 Gbps | 25 Gbps | 50 Gbps | 100 Gbps | 100 Gbps | 200 Gbps | 400 Gbps |
| 調變技術 | NRZ | NRZ | NRZ | PAM4 | PAM4 | PAM4 | PAM6 (E) |
註: (E) 表示「估計」。
(來源:TrendForce)
綜上所述,InfiniBand 擁有極低延遲、無丟包風險的原生優點,因此在現今的 AI 資料中心中仍被廣泛採用;然而,其硬體與運維成本較高,以及供應商有限。而在 Ethernet 上使用 RoCE v2 協定的效能雖然仍不如 InfiniBand,卻具有生態系開放,以及硬體與運維成本較低的優勢,使得大家開始轉向採用 Ethernet 架構。
表 3. AI 資料中心網路 InfiniBand 與 Ethernet 關鍵技術比較
| 協議 | InfiniBand (RDMA) | Ethernet (RoCE v2) |
|---|---|---|
| 延遲 | <2us | <5us |
| 目前主流頻寬/Port | 800 Gbps | 800 Gbps |
| 無丟包機制 | Credit-Based Flow Control (CBFC) | Ethernet Flow Control (802.3x)、PFC、ECN |
| 生態系 | 封閉 (NVIDIA) | 開放 |
| 硬體成本 | 高 (1x) | 低 (1/3) |
(來源:TrendForce)
如今,AI 資料中心需求擴張,加上成本與生態考量,NVIDIA 開始進軍 Ethernet 市場。NVIDIA 目前除了自有的 InfiniBand Switch Quantum 系列,也提供 Ethernet 產品 Spectrum 系列。
今年推出的 Quantum-X800 可提供 800 Gbps/Port × 144 個 Port,總頻寬共 115.2 Tbps;Spectrum-X800 可提供 800 Gbps/Port × 64 個 Port,總頻寬共 51.2 Tbps,並預計分別在 2H25、2H26 推出 Quantum-X800 與 Spectrum-X800 的 CPO(Co-Packaged Optics)版本。
儘管 Spectrum 相較其他廠商的 Ethernet Switch 價格較高,NVIDIA 的優勢在於產品能與其軟硬體深度整合,例如搭配 BlueField-3 DPU 與 DOCA 2.0 平台,以實現高效自適應路由(Adaptive Routing)等技術。
Switch IC 成本與 CPO 布局競賽:Ethernet 陣營領跑,InfiniBand 緊追
在 Ethernet 領域,Broadcom 仍是 Ethernet Switch 的技術領先者,其 Tomahawk 系列 Switch IC 遵循「每兩年總頻寬翻倍」的規律。至 2025 年,Broadcom 首次推出全球總頻寬最大的 Switch IC Tomahawk 6,總頻寬達 102.4 Tbps,可支援 1.6 Tbps/Port × 64 Port。此外,Tomahawk 6 同步支援超 UEC 1.0 協議,可採用多路徑封包噴灑(Multipath Spraying)、LLR、CBFC 等功能,進一步降低延遲與丟包風險。
Broadcom 也在 CPO 技術上領先,自 2022 年起推出 CPO 版本的 Tomahawk 4 Humboldt,2024 年推出 Tomahawk 5 Bailly,並持續在 2025 年推出 Tomahawk 6 Davisson,鞏固其在 Ethernet 硬體整合的領先地位。
表 4. Scale-Out Switch IC 比較:Broadcom、NVIDIA、Marvell、Cisco
| 供應商 | Broadcom | NVIDIA | Marvell | Cisco | |||||
|---|---|---|---|---|---|---|---|---|---|
| 產品 | Tomahawk 5 | Tomahawk 6 | Tomahawk 6 (CPO) | Quantum-3 | Quantum-3 (CPO) | Spectrum-4 | Spectrum-4 (CPO) | Teralynx 10 | Cisco Silicon One G200 |
| 推出時間 | 2023 | 2025 | 2025 | 2024 | 2025 | 2024 | 2026 | 2024 | 2023 |
| 製程節點 | N5 | N3 | N3 | N4 | N4 | N4 | N4 | N5 | N5 |
| 單晶片頻寬 | 51.2 Tbps | 102.4 Tbps | 102.4 Tbps | 28.8 Tbps | 28.8 Tbps | 51.2 Tbps | 102.4 Tbps | 51.2 Tbps | 51.2 Tbps |
(來源:TrendForce)
相較於 Broadcom 今年首先推出 102.4 Tbps 的 Tomahawk 6,NVIDIA 預計於 2026 下半年才推出 102.4 Tbps 的 Spectrum-X1600,技術仍落後 Broadcom 約一年。
在 CPO 方面,NVIDIA 預計在 2026 下半年同步推出 CPO 版本的 102.4 Tbps Spectrum-X Photonics,追趕 Broadcom 的腳步。
表 5. NVIDIA Scale-Out 網路發展路徑
| 時間 | 1H25 | 2H25 | 2H26 | 2H27 | 2028 |
|---|---|---|---|---|---|
| 平台 | Blackwell | Blackwell Ultra | Rubin | Rubin Ultra | Feynman |
| InfiniBand Switch | |||||
| Switch | Quantum-2 | Quantum-X800 | Quantum-X1600 | Quantum-X3200 | |
| 總頻寬 | 51.2 Tbps | 115.2 Tbps | 230.4 Tbps | - | |
| 頻寬/Port | 400 Gbps | 800 Gbps | 1.6 Tbps | 3.2 Tbps | |
| Ethernet Switch | |||||
| Switch | Spectrum-X800 | Spectrum-X1600 | Spectrum-X3200 | ||
| 總頻寬 | 51.2 Tbps | 102.4 Tbps | 204.8 Tbps | ||
| 頻寬/Port | 800 Gbps | 1.6 Tbps | 3.2 Tbps | ||
| 網路介面卡(NIC) | |||||
| SuperNIC | ConnectX-8 | ConnectX-9 | ConnectX-10 | ||
| 頻寬/Port | 800 Gbps | 1.6 Tbps | 3.2 Tbps | ||
| 頻寬/Lane | 200 Gbps | 200 Gbps | 400 Gbps | ||
| PCIe 規格 | PCIe 6.0 (48 lanes) | PCIe 7.0 (48 lanes) | PCIe 8.0 | ||
(來源:TrendForce)
除了 Broadcom、NVIDIA 二大陣營,還有其它供應商也加入角逐行列,Marvell 於 2023 年推出總頻寬 51.2 Tbps 的 Teralynx 10,以及 Cisco 也在 2023 年推出總頻寬 51.2 Tbps 的 Cisco Silicon One G200 系列,並推出他們的 CPO 原型機。
電通訊極限逼近,光學整合成為新戰場
傳統資料傳輸多使用銅纜的電通訊,然而隨著傳輸距離需求增加,光纖傳輸的光通訊在 Scale-Out 場景中逐漸展現優勢。與電通訊相比,光通訊具備低損耗、高頻寬、不易受電磁干擾以及長距離傳輸等特性,如表 6 所示。
表 6. 電通訊與光通訊架構比較
| 技術 | 電通訊 | 光通訊 |
|---|---|---|
| 媒介 | 銅纜 | 光纖 |
| 主流傳輸速率 | 56–112 Gbps | 200 Gbps |
| 互連距離 | ≤100 m (視傳輸速度影響距離) | MMF(SR):50–100 m SMF(DR/FR):500 m–2 km SMF(LR/ER/ZR):10–80+ km |
| 功耗 | 高頻下功耗高 | 元件功耗高,但封裝整合可降低總功耗 |
| 穩定性 | 易受電磁干擾 | 不受電磁干擾 |
| 成本 | 短距離最低成本、連接簡單 | 初始成本較高,但距離/密度擴展性佳 |
(來源:TrendForce)
目前光通訊多採用可插拔式(Pluggable)的光收發模組(Optic Transceiver)進行光電訊號轉換,傳輸速率已提升至 200 Gbps/Lane,總頻寬可達 1.6 Tbps(8 × 200 Gbps)。
隨著速率提升,功耗增加、電路板上的訊號損耗問題也愈發明顯。矽光子(Silicon Photonics, SiPh)技術正是為解決這些問題而誕生。
矽光子技術就是將光收發模組元件微縮並整合進矽晶片,形成如下圖光子積體電路(Photonic Integrated Circuit, PIC),再進一步封裝在晶片內,縮短電路距離並改以光路傳輸,這種封裝方式即為共同封裝光學(Co-Packaged Optics, CPO)。
圖 3
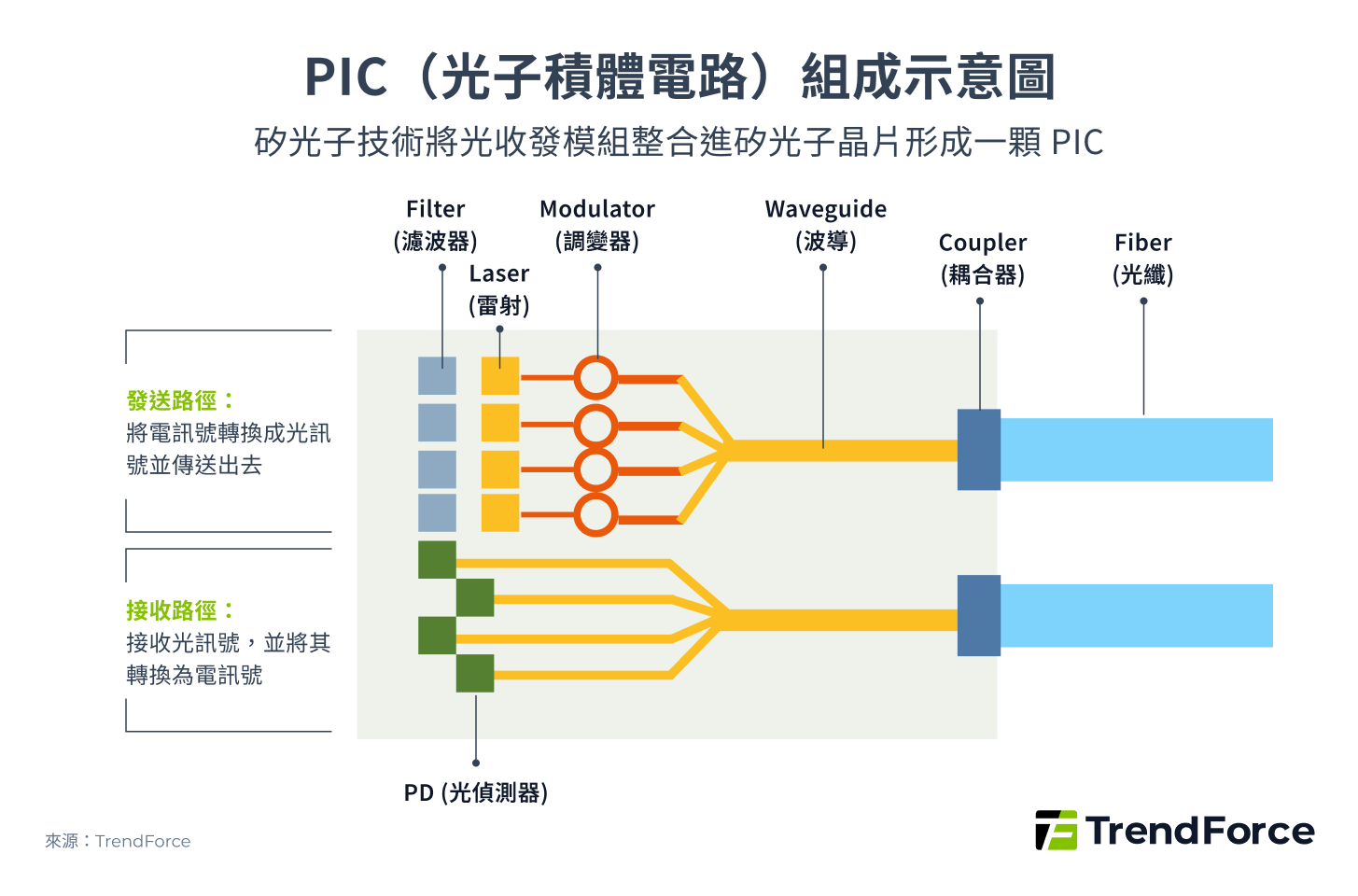
廣義的 CPO 如下圖 4,包含多種封裝形式,包括 OBO(On-Board Optics)、CPO 以及 OIO(Optical I/O)。
圖 4
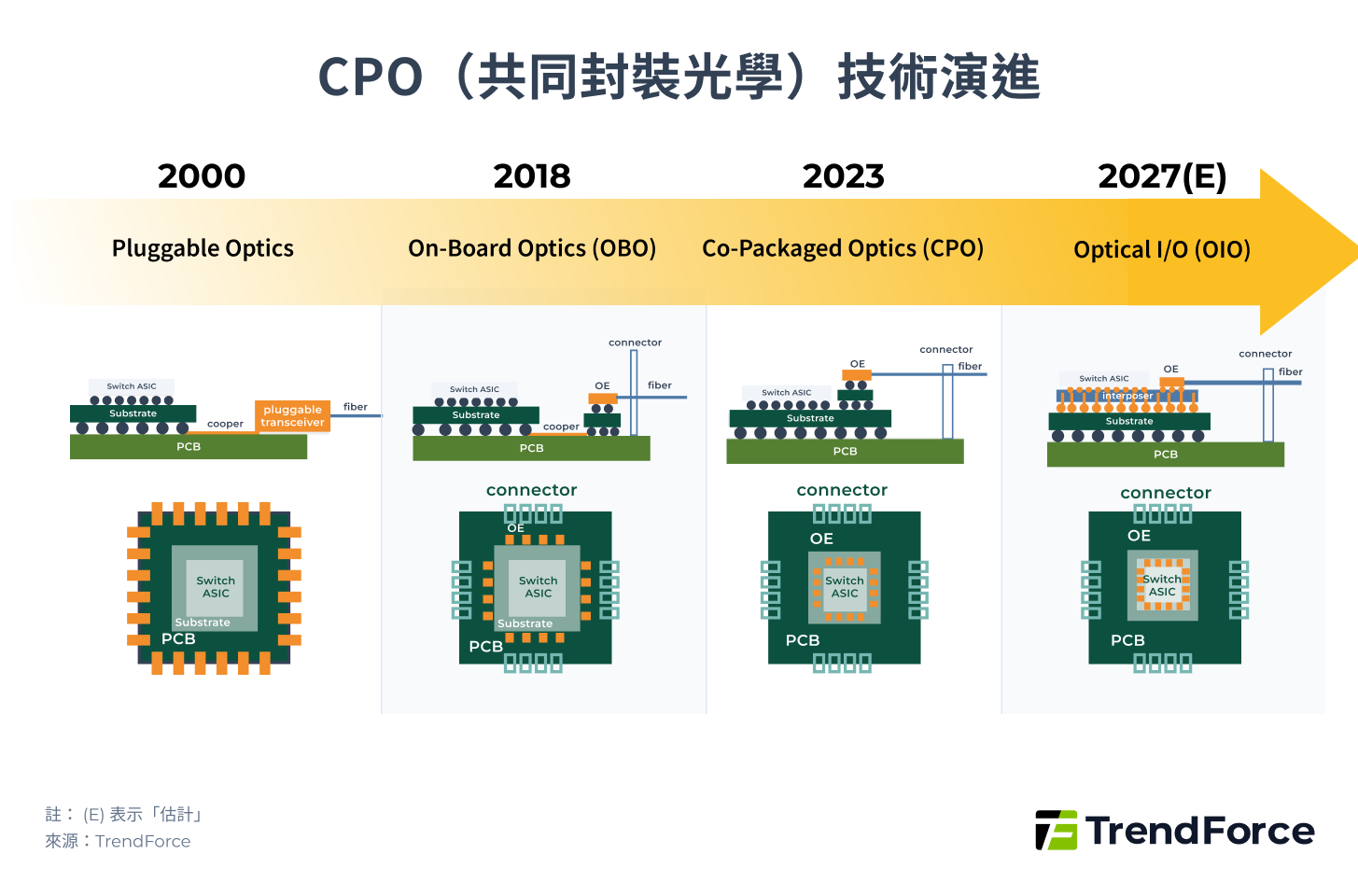
上圖 4 可見,光引擎(Optical Engine,OE)的封裝位置呈現逐步靠近主要 ASIC 的趨勢,演進細節如下:
- OBO:將 OE 封裝於 PCB 板上,現今較少使用。
- 狹義 CPO:將 OE 封裝於基板(Substrate)上,為目前主流方案。相較於可插拔模組,功耗降至 <0.5 倍 (~5 pJ/bit)、延遲降至 <0.1 倍 (~10 ns)。
- OIO:將 OE 封裝於中介層(Interposer)上,為未來發展方向。相較於可插拔模組,功耗降至 <0.1 倍 (<1 pJ/bit)、延遲降至 <0.05 倍 (~5 ns)。
然而,CPO 仍有散熱、鍵合、耦合等技術挑戰,隨著電通訊逼近極限,CPO 與矽光子技術的突破將決定未來 Scale-Out 網路的新戰場。
2025 全球 AI 伺服器趨勢:CSP 加速投資與自研 ASIC
誰正主導下一波 AI 基礎建設投資?雲端巨頭資本支出全面升溫,整櫃 GPU、自研晶片與液冷系統成為核心戰場。揭開下一代 AI 資料中心的投資策略。
了解趨勢Ethernet 陣營集結:UEC 推動 UEC 1.0 標準
正如前述,InfiniBand 的極低延遲特性,使其在生成式 AI 發展初期搶下大量市占率。然而,Ethernet 生態系作為高效能網路的主流之一,也為實現極低延遲,在 2023 年 8 月成立了超乙太網路聯盟(Ultra Ethernet Consortium,UEC),初始成員包括 AMD、Arista、Broadcom、Cisco、Eviden、HPE、Intel、Meta、Microsoft 等 9 家大廠。
相較於以 NVIDIA 為首的 InfiniBand 生態系,UEC 強調開放標準與互操作性,避免被單一供應商綁定。
UEC 於 2025 年 6 月發佈了 UEC 1.0,這不是僅在 RoCE v2 基礎上的改良,而是在軟體層(Software)、傳輸層(Transport)、網路層(Network)、連結層(Link)與物理層(Physical)等所有層級重新建構。
圖 5
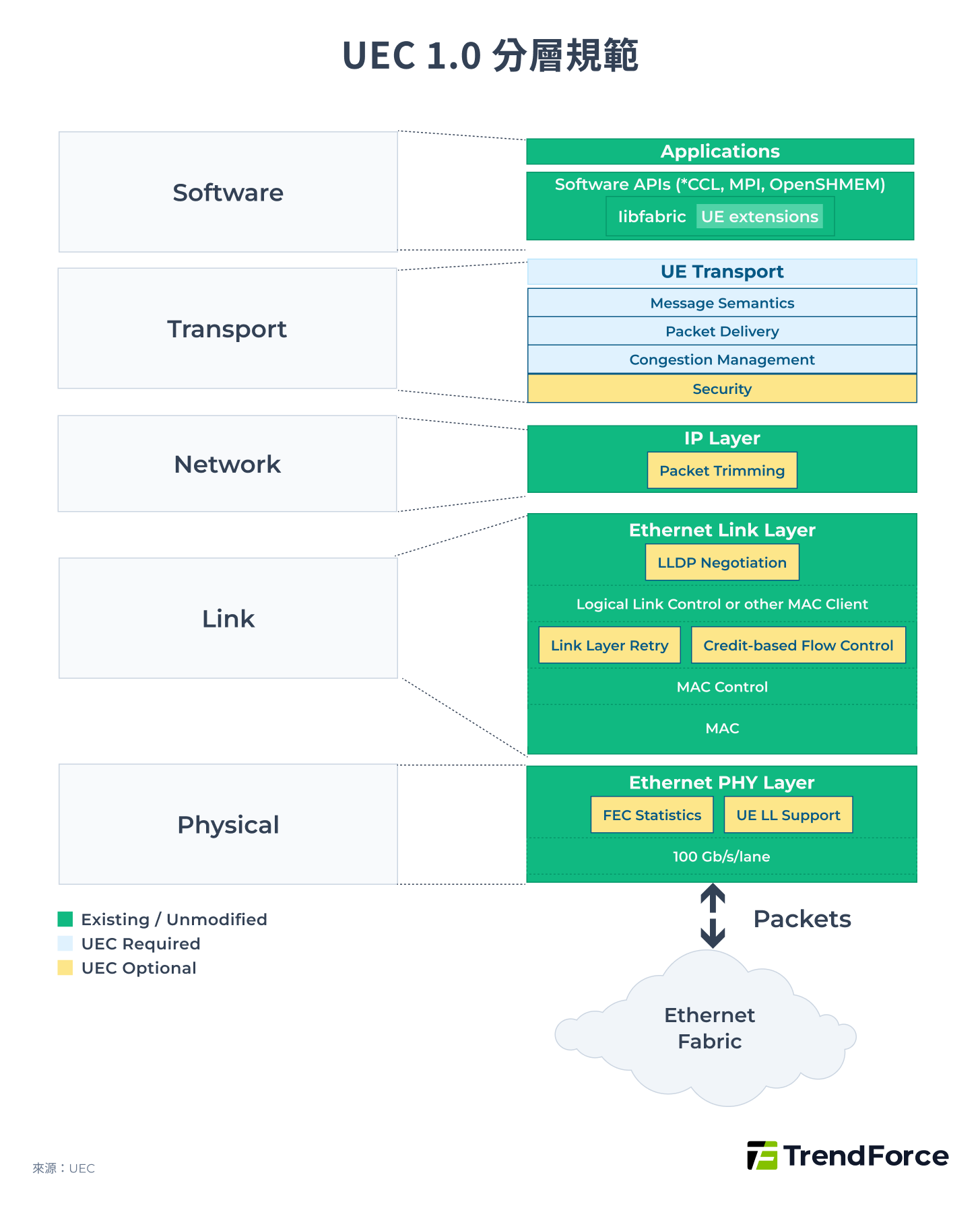
其中,降低延遲的關鍵更動在於在 Transport 層新增封包傳輸子層(Packet Delivery Sublayer, PDS)功能,主要特點為:
- 採用多路徑傳輸(Multipath),即端點之間有多條等距等速的路徑(Rail/Lane)。
- NIC 透過分配一個熵值(Entropy)將封包噴灑到所有 Lane 上,使其透過並聯獲得更大頻寬。
這樣的多層結構可加快網路恢復速率,如快速替換遺失封包,以確保流量順暢,近似 InfiniBand 的自適應路由。
另一方面,在降低丟包風險上,UEC 1.0 主要有 2 項更動:
- 在 Link Layer 加入可選的 Link Layer Retry(LLR)功能,即封包遺失時可以在本地 Link 端快速請求重傳,降低對基於優先及的流量管控(Priority Flow Control, PFC)機制的依賴。
- 在 Link Layer 加入可選的基於信用的流量控制(Credit-Based Flow Control, CBFC)功能,即發送端必須先獲得接收端的 Credit 才能傳送資料,接收端處理完畢並釋放空間後回傳新的 Credit ,以達到流量控制與無丟包風險,近似 InfiniBand 的 CBFC。
中國 Scale-Out 自成一格:Ethernet 標準化與自研技術並行
中國的 AI 基礎建設 Scale-Out 架構朝向「自主可控 + 國際兼容」發展,除了遵循國際 Ethernet 標準化的同時,國內各大廠也積極投入自研架構,逐步形成具本土特色的 Scale-Out 架構體系。
阿里巴巴、百度、華為、騰訊等主要科技大廠選擇加入 UEC,共同推動 UEC 的制定。除了參與標準化,中國主要廠商也各自開發自研 Scale-Out 架構,普遍以「低延遲、零丟包」為目標,直接對標 InfiniBand。
表 7. 中國的 Scale-Out 與 UEC 架構比較
| 協議 | UEC 1.0 | GSE 2.0 (中國移動) |
HPN 7.0 (阿里雲) |
UB 1.0 (華為) |
|---|---|---|---|---|
| 延遲 | <2us | <2us | <2us | <2us |
| 主流 BW | 800 Gbps | 800 Gbps | 400 Gbps | 400 Gbps |
| 無丟包機制 | Link Layer Retry (LLR)、Credit-Based Flow Control (CBFC) | DGSQ 流量管制 | Solar-RDMA、「雙平面」分配流量 | Link Layer Retry (LLR) |
| 生態系 | 開放 | 開放 | 開放 | 封閉 |
(來源:TrendForce)
這些自研技術架構的具體細節如下:
- 中國移動:全調度乙太網(GSE)
中國移動於 2023 年 5 月率於 UEC 架構前推出 GSE,分為兩個階段:- GSE 1.0 在現有 RoCE 網路基礎上優化,透過端口級負載均衡、端網協同的壅塞感知等,提升資料傳輸穩定性與整體性能,減少算力浪費。
- GSE 2.0 是全面重構網路設計,從控制、傳輸到運算層重新建立協議,導入 Multipath Spraying 與流量管控機制(DGSQ)使更有效分配流量,進一步降低延遲與丟包風險,以滿足未來 AI 運算中心的高性能需求。
- 阿里雲:高性能網路(HPN)
阿里雲的 HPN 7.0 架構採用了「雙上聯 + 多軌 + 雙平面」設計,透過雙上聯提升網路性能、多軌允許封包平行傳輸、雙平面強化網路穩定性。而下一代 HPN 8.0 計畫採用全自研硬體,如 102.4 Tbps Switch IC,實現 800Gbps 頻寬,對標國際方案。 - 華為:UB-Mesh 互連架構
華為的 Ascend NPU 平台中部署自研的 UB-Mesh 架構,採用多維度 nD-Full Mesh 拓撲設計,具備橫向 Scale-Up 與縱向擴展 Scale-Out 能力。當拓展至 3D 以上結構時,即達到 Scale-Out 層級,可支撐超大規模 AI 訓練叢集。
中國的自研 Scale-Out 架構持續發展,預期將為中國本地廠商提供更大的成長空間,隨著中際旭創、光迅科技等企業的加入,本土光模組與矽光技術有望形成完整產業鏈,推動中國在 AI 基礎網路領域走向自成一格的路線。

AI 資料中心的技術轉型與供應鏈機會
長期以來,NVIDIA 的 InfiniBand 以極低延遲(<2μs)與零丟包優勢,主導 AI 資料中心的 Scale-Out 市場。然而,隨著 UEC 於 2025 年 6 月發佈 UEC 1.0 標準,Ethernet 網路力求與 InfiniBand 相當的低延遲與高穩定性,正逐步重獲市場競爭力。同時,Broadcom 依循「Switch IC 頻寬每兩年翻倍」的發展節奏,使 Ethernet 的硬體基礎不斷躍升。
隨著傳輸速率提升至 1.6 Tbps 或以上,傳統可插拔光模組的功耗與延遲成為瓶頸,CPO 技術因此逐步成為高性能網路標準。CPO 將光收發元件直接整合至 Switch 晶片基板上,大幅降低功耗與延遲。Broadcom 在 CPO 領域領先,已自 2022 年起推出多代 CPO 版本 Switch。NVIDIA 也將於 2025 下半年推出 InfiniBand CPO 產品,CPO 將逐漸成為主流網路架構。
隨著 Ethernet 與 CPO 技術的成熟,AI 資料中心網路正全面邁向高速光通訊化,帶動光收發模組與上游供應鏈(矽光子晶片、雷射光源、光纖模組等)的新的成長機會。
預計在 Scale-Out 架構中,Nvidia 將持續主導傳統 InfiniBand 市場;而在 Ethernet 領域,Broadcom 將依靠領先的高頻寬 Switch IC、CPO 技術及 UEC 標準的落地,持續掌握主要市場份額。
NVIDIA 和 Broadcom 在 2025 年 8 月不約而同地提出了 Scale-Across 的概念,目標是將規模進一步擴展至跨資料中心互連,未來將實現更大規模 GPU 互連與更長距離傳輸,推動高性能網路與資料中心架構的新格局。
ASIC 將超車 GPU?NVIDIA 從 Scale-Up 霸主到全面戰爭
ASIC 成長率 2026 年將超車 GPU,NVIDIA 面臨前所未有的競爭壓力。戰局已從晶片性能轉向互連網路、核心交換器、軟體與生態系的全面之爭!
揭開 NVIDIA AI 策略