TurboQuant重塑AI推理:記憶體需求擴張解析
發佈日期
2026-03-27
更新頻率
不定期
報告格式
TurboQuant以無損降維壓縮技術突破語言模型推理的記憶體瓶頸,大幅提升運算效能。成本下降反激發長序列應用需求,全面帶動雲端與邊緣端對高頻寬、主記憶體及快閃記憶體的規格升級與長期需求擴張。
重點摘要
- 技術突破:利用降維原理壓縮注意力向量,免重訓且近乎無損精度,大幅節省記憶體並倍速提升推理效能。
- 重塑市場:依據謝隆悖論,推理成本驟降反激發長序列與多代理系統的龐大需求,加速人工智慧向邊緣端落地。
- 軟硬協同:有別於傳統流程優化或低位元量化,其從改變資料表徵切入,未來有望成為晶片加速單元標配。
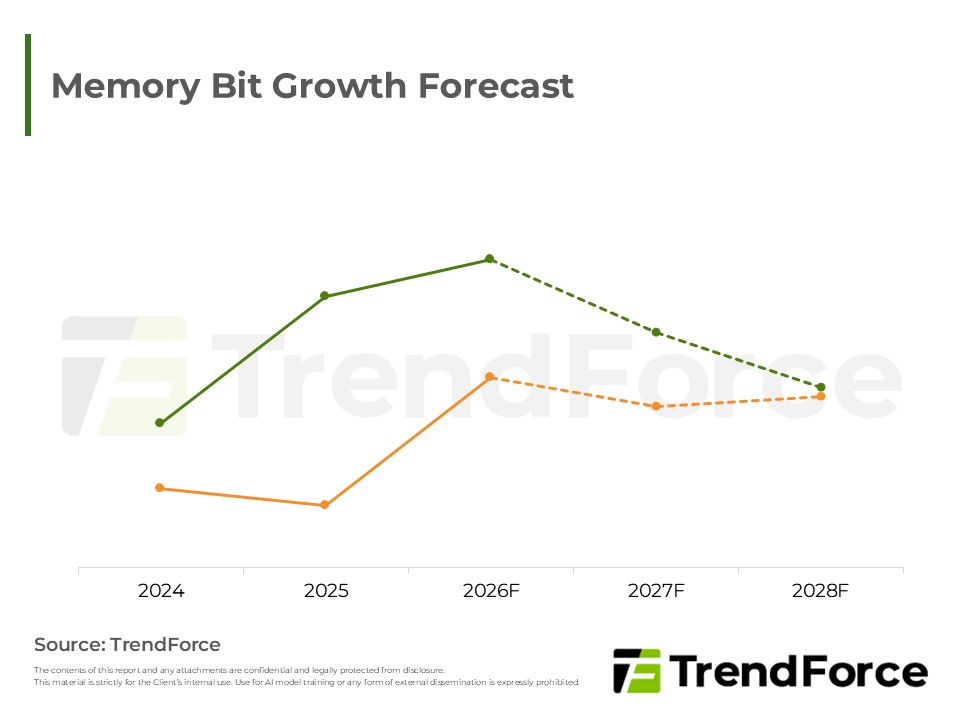
- 需求擴張:快取壓力緩解極大化既有資源效益,不僅未減弱高頻寬記憶體需求,更全面推升動態隨機存取記憶體與快閃記憶體做為運算延伸層的容量升級。
目錄
- TurboQuant突破KV Cache瓶頸,AI推理效率躍升並推動記憶體需求長期擴張
- 從管理優化走向內容降維,有望成軟硬體協同設計標配
- KV Cache壓力緩解下,記憶體需求結構持續擴張
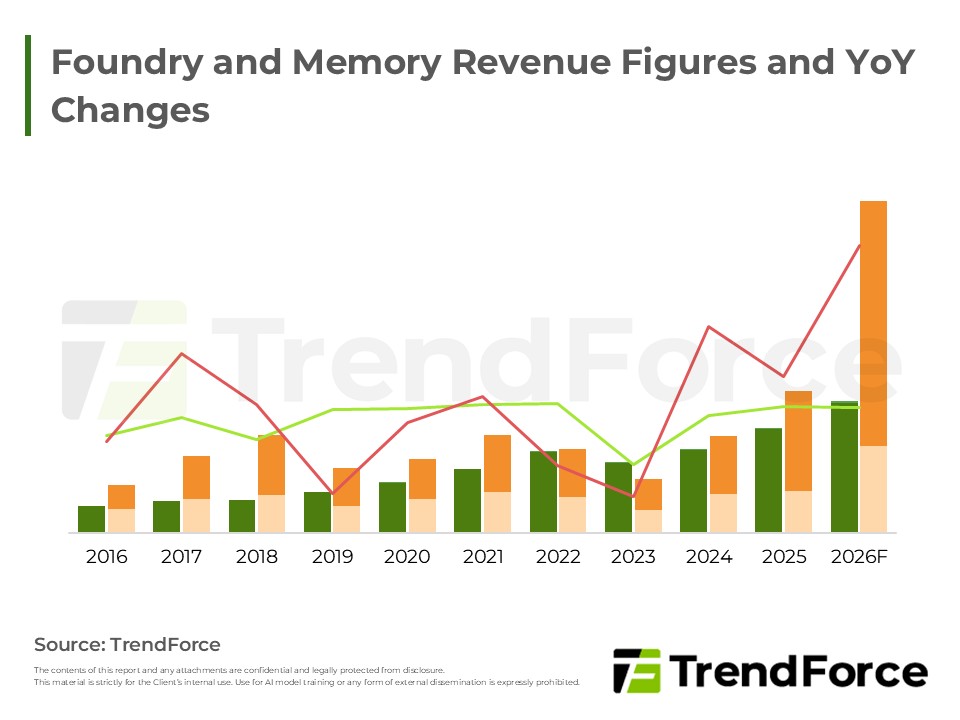
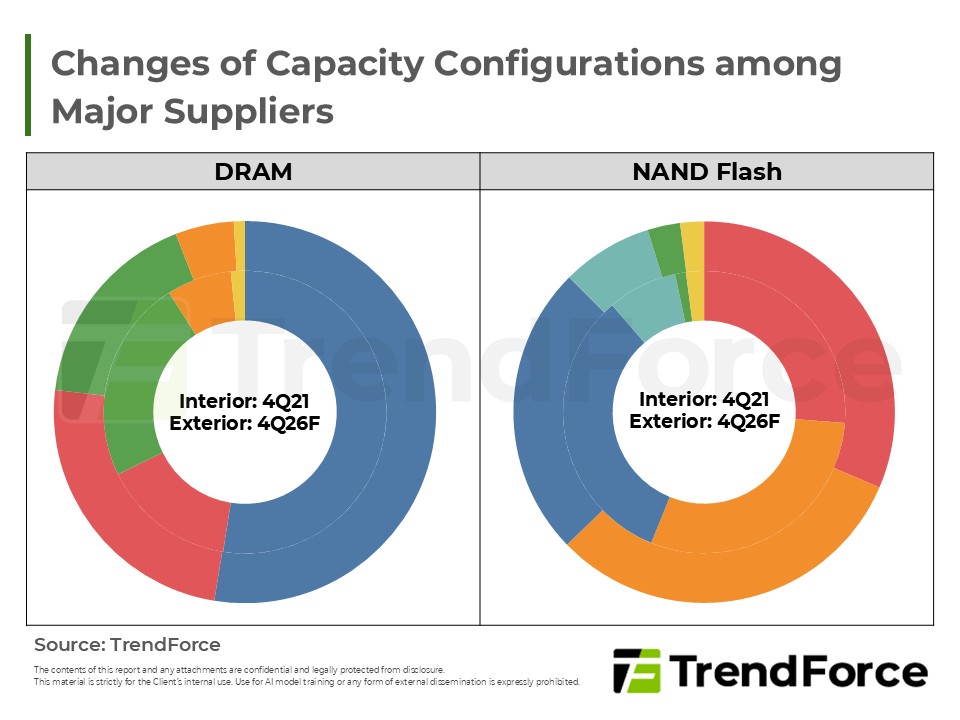
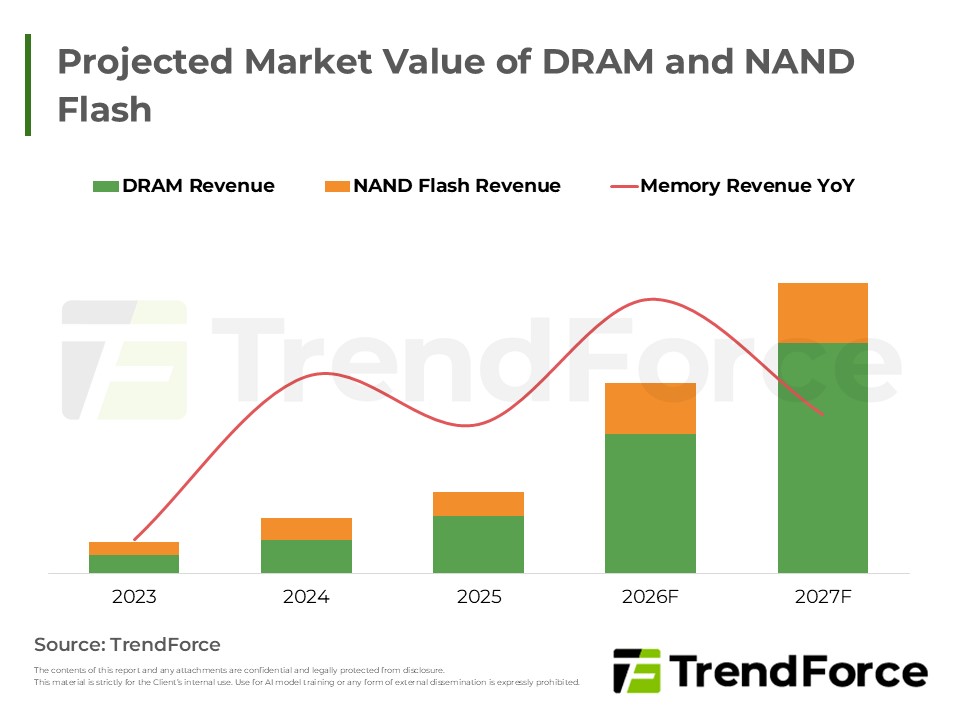
- 從主系統記憶體到運算延伸層,DRAM與NAND Flash角色持續升級
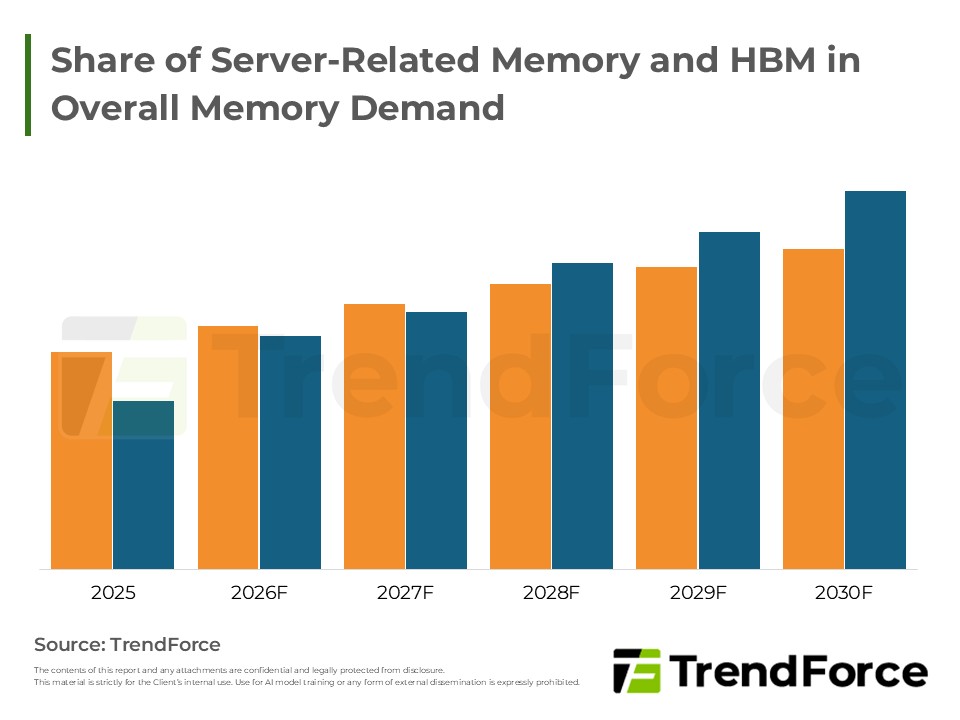
- Share of Server-Related Memory and HBM in Overall Memory Demand
<Total Pages: 5>
報告分類: DRAM , NAND Flash , AI/HBM/Server